Show the code
pacman::p_load(sf, tmap, tidyverse)Choropleth mapping involves the symbolisation of enumeration units, such as countries, provinces, states, counties or census units, using area patterns or graduated colors.
E.g., use a choropleth map to portray the spatial distribution of aged population of <country>.
This exercise focuses on usage of tmap package to create choropleth map.
Master Plan 2014 Subzone Boundary (Web) : (i.e. MP14_SUBZONE_WEB_PL) in ESRI shapefile format from data.gov.sg
This is a geospatial data.
Consists of the geographical boundary of Singapore at the planning subzone level. The data is based on URA Master Plan 2014.
Singapore Residents by Planning Area / Subzone, Age Group, Sex and Type of Dwelling, June 2011-2020 : csv format (i.e. respopagesextod2011to2020.csv) from Department of Statistics, Singapore
This is an aspatial data file.
Although it does not contain any coordinates values, but it’s PA and SZ fields can be used as unique identifiers to geocode to MP14_SUBZONE_WEB_PL shapefile.
popdata <- read_csv("data/aspatial/respopagesextod2011to2020.csv")Rows: 984656 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): PA, SZ, AG, Sex, TOD
dbl (2): Pop, Time
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Prepare data table to plot thematic map. The variables are :
young : age group 0 to 4 until age groyup 20 to 24,
economy active : age group 25-29 until age group 60-64,
aged: age group 65 and above,
total : all age group, and
dependency : the ratio between young and aged against economy active group
pivot_wider(
data,
id_cols = NULL, id_expand = FALSE, names_from = name, names_prefix = "",
names_sep = "_", names_glue = NULL, names_sort = FALSE, names_vary = "fastest",
names_expand = FALSE, names_repair = "check_unique", values_from = value,
values_fill = NULL, values_fn = NULL, unused_fn = NULL, ...
)
arguments :
* data = A data frame to pivot.
* id_cols = A set of columns that uniquely identifies each observation.
>> Defaults to all columns in data except for the columns specified in names_from and values_from.
>> Typically used when have redundant variables, i.e. variables whose values are perfectly correlated with existing variables.
* id_expand = Should the values in the id_cols columns be expanded by expand() before pivoting?
>> This results in more rows, the output will contain a complete expansion of all possible values in id_cols.
>> Implicit factor levels that aren't represented in the data will become explicit.
>> Additionally, the row values corresponding to the expanded id_cols will be sorted.
* names_from, values_from = A pair of arguments describing which column (or columns) to get the name of the output column (names_from), and which column (or columns) to get the cell values from (values_from).
>> If values_from contains multiple values, the value will be added to the front of the output column.more arguments for pivot_wider() …
mutate(.data, ...,
.keep = c("all", "used", "unused", "none"),
.before = NULL,
.after = NULL
)
arguments :
* data = A data frame, data frame extension (e.g. a tibble), or a lazy data frame (e.g. from dbplyr or dtplyr)
* ... = Name-value pairs. The name gives the name of the column in the output.
* keep = Control which columns from .data are retained in the output.
>> Grouping columns and columns created by ... are aways kept.
"all" retains all columns from .data. This is the default.
"used" retains only the columns used in ... to create new columns. This is useful for checking your work, as it displays inputs and outputs side-by-side.
"unused" retains only the columns not used in ... to create new columns. This is useful if you generate new columns, but no longer need the columns used to generate them.
"none" doesn't retain any extra columns from .data. Only the grouping variables and columns created by ... are kept.
* .before, .after = Optionally, control where new columns should appear (the default is to add to the right hand side).poptest <- popdata %>%
filter(Time == 2020) %>%
group_by(PA, SZ, AG) %>%
summarise(`POP` = sum(`Pop`)) %>%
ungroup() %>%
pivot_wider(names_from = AG,
values_from = POP)`summarise()` has grouped output by 'PA', 'SZ'. You can override using the
`.groups` argument.popdata2020 <- popdata %>%
filter(Time == 2020) %>%
group_by(PA, SZ, AG) %>%
summarise(`POP` = sum(`Pop`)) %>%
ungroup()%>%
pivot_wider(names_from=AG,
values_from=POP) %>%
mutate(YOUNG = rowSums(.[3:6])
+rowSums(.[12])) %>%
mutate(`ECONOMY ACTIVE` = rowSums(.[7:11])+
rowSums(.[13:15]))%>%
mutate(`AGED`=rowSums(.[16:21])) %>%
mutate(`TOTAL`=rowSums(.[3:21])) %>%
mutate(`DEPENDENCY` = (`YOUNG` + `AGED`)
/`ECONOMY ACTIVE`) %>%
select(`PA`, `SZ`, `YOUNG`,
`ECONOMY ACTIVE`, `AGED`,
`TOTAL`, `DEPENDENCY`)`summarise()` has grouped output by 'PA', 'SZ'. You can override using the
`.groups` argument.![]() Useful mutate functions :
Useful mutate functions :
+, -, log( ), etc., for their usual mathematical meanings
lead( ), lag( )
dense_rank( ), min_rank( ), percent_rank( ), row_number( ), cume_dist( ), ntile( )
cumsum( ), cummean( ), cummin( ), cummax( ), cumany( ), cumall( )
na_if( ), coalesce( )
if_else( ), recode( ), case_when( )
The 3 scoped variants of mutate( ) to transform multiple variables :
_all affects every variable
_at affects variables selected with a character vector or vars()
_if affects variables selected with a predicate function.
mutate_at(.tbl, .vars, .funs, ..., .cols = NULL)
arguments :
* .tbl = A tbl object.
* .funs = A function, a quosure style lambda ~ fun(.) or a list of either form.
>> can be a named or unnamed list. If a function is unnamed and the name cannot be derived automatically, a name of the form "fn#" is used.
* ... = Additional arguments for the function calls in .funs. These are evaluated only once, with tidy dots support.
*.vars = A list of columns generated by vars(), a character vector of column names, a numeric vector of column positions, or NULL.
* .cols = This argument has been renamed to .vars to fit dplyr's terminology and is deprecated.[Before the georelational join, convert the values in PA and SZ fields to uppercase.]{style=“color:#9e6024”}
popdata2020 <- popdata2020 %>%
mutate_at(.vars = vars(PA, SZ),
.funs = funs(toupper)) %>%
filter(`ECONOMY ACTIVE` > 0)Warning: `funs()` was deprecated in dplyr 0.8.0.
ℹ Please use a list of either functions or lambdas:
# Simple named list: list(mean = mean, median = median)
# Auto named with `tibble::lst()`: tibble::lst(mean, median)
# Using lambdas list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))[To ensure the output is a simple features data frame, join data and attribute table using planning subzone name e.g. SUBZONE_N and SZ as the common identifier.]{style=“color:#9e6024”}
mpsz_pop2020 <- left_join(mpsz, popdata2020,
by = c("SUBZONE_N" = "SZ"))
write_rds(
x, file, compress = c("none", "gz", "bz2", "xz"), version = 2,
refhook = NULL, text = FALSE, path = deprecated(), ...
)
arguments :
* file = The file path to read from/write to.
* refhook = A function to handle reference objects.
* x = R object to write to serialise.
* compress = Compression method to use: "none", "gz" ,"bz", or "xz".
* version = Serialization format version to be used. The default value is 2 as it's compatible for R versions prior to 3.5.0. See base::saveRDS() for more details.
* text = If TRUE a text representation is used, otherwise a binary representation is used.
* path = [Deprecated] Use the file argument instead.
* ... = Additional arguments to connection function. For example, control the space-time trade-off of different compression methods with compression. See connections() for more details.write_rds(mpsz_pop2020, "data/rds/mpszpop2020.rds")2 tmap approaches to prepare thematic map :
plot thematic map quickly using qtm( ).
plot highly customisable thematic map.
qtm(
shp, fill = NA, symbols.size = NULL, symbols.col = NULL, symbols.shape = NULL,
dots.col = NULL, text = NULL, text.size = 1, text.col = NA, lines.lwd = NULL,
lines.col = NULL, raster = NA, borders = NA, by = NULL, scale = NA, title = NA,
projection = NULL, bbox = NULL, basemaps = NA, overlays = NA, style = NULL,
format = NULL, ...
)
arguments :
* shp = One of -
>> shape object, which is an object from a class defined by the sf or stars package. Objects from the packages sp and raster are also supported, but discouraged.
>> Not specified, i.e. qtm() is executed. In this case a plain interactive map is shown.
>> A OSM search string, e.g. qtm("Amsterdam"). In this case a plain interactive map is shown positioned according to the results of the search query (from OpenStreetMap nominatim)
* fill = either a color to fill the polygons, or name of the data variable in shp to draw a choropleth.
>> Only applicable when shp contains polygons.
>> Set fill = NULL to draw only polygon borders. See also argument borders.tmap_mode("plot")tmap mode set to plottingqtm(mpsz_pop2020,
fill = "DEPENDENCY")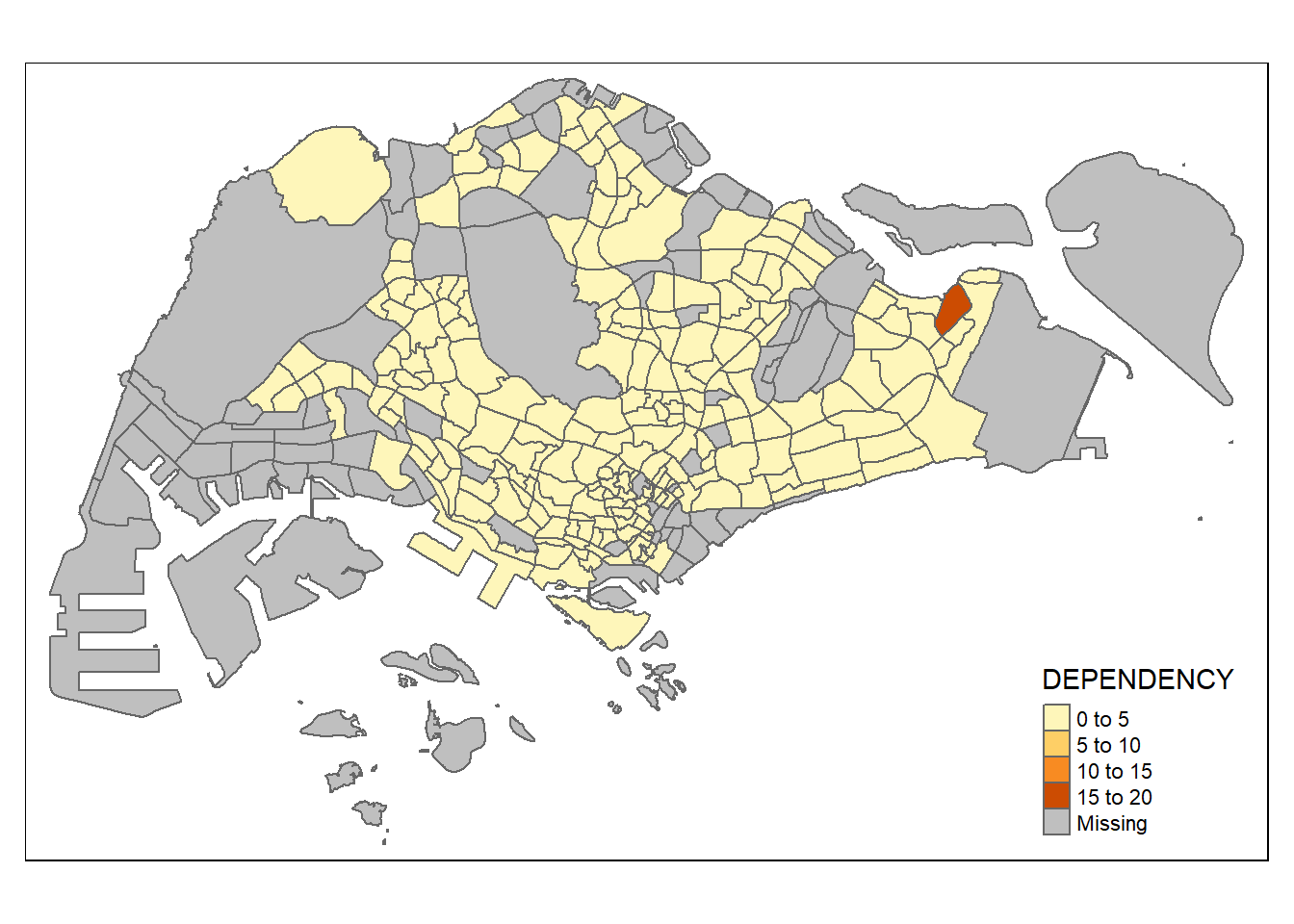
Arguments for the following function :
argument :
* style = method to process the color scale when col is a numeric variable.
>> Discrete gradient options are "cat", "fixed", "sd", "equal", "pretty", "quantile", "kmeans", "hclust", "bclust", "fisher", "jenks", "dpih", "headtails", and "log10_pretty".
>> A numeric variable is processed as a categorical variable when using "cat", i.e. each unique value will correspond to a distinct category.
>> For the other discrete gradient options (except "log10_pretty"), see the details in classIntervals (extra arguments can be passed on via style.args).
>> Continuous gradient options are "cont", "order", and "log10".
>> The numeric variable can be either regarded as a continuous variable or a count (integer) variable.
* legend.hist = logical that determines whether a histogram is shown.
* legend.hist.z = index value that determines the position of the histogram legend element.
* legend.is.portrait = logical that determines whether the legend is in portrait mode (TRUE) or landscape (FALSE).tm_layout( ) - layout of cartographic map.
tm_borders( ) - draw polygon borders.
tm_borders(col = "grey40", lwd = 1, lty = "solid", alpha = NA)
argument :
* alpha = transparency number between 0 (totally transparent) and 1 (not transparent).
>> By default, the alpha value of the col is used (normally 1).
* col = border colour.
* lwd = border line width.
* lty = border line type.
tm_compass(north = 0, type = NA, text.size = 0.8, size = NA,
show.labels = 1, cardinal.directions = c("N", "E", "S", "W"),
text.color = NA, color.dark = NA, color.light = NA, lwd = 1,
position = NA, bg.color = NA, bg.alpha = NA, just = NA,
fontsize = NULL
)
arguments :
* type = compass type : "arrow", "4star", "8star", "radar", "rose". >> The default is controlled by tm_layout (which uses "arrow" for the default style)
* size = size of the compass in number of text lines.
>> The default values depend on the type: for "arrow" it is 2, for "4star" and "8star" it is 4, and for "radar" and "rose" it is 6.tm_scale_bar( ) - scale bar.
tm_grid( ) - draw coordinate grid / graticule lines.
tm_grid(x = NA, y = NA, n.x = NA, n.y = NA, projection = NA,
col = NA, lwd = 1, alpha = NA, labels.size = 0.6, labels.col = NA,
labels.rot = c(0, 0), labels.format = list(big.mark = ","),
labels.margin.x = 0, labels.margin.y = 0, labels.inside.frame = TRUE)
argument :
* alpha = transparency of the grid lines. Number between 0 and 1.
>> By default, the alpha transparency of col is taken.
tm_credits(text, size = 0.7, col = NA, alpha = NA, align = "left",
bg.color = NA, bg.alpha = NA, fontface = NA, fontfamily = NA,
position = NA, width = NA, just = NA
)
argument :
* position = position of the text. Vector of two values, specifying the x and y coordinates.
>> first value can be "left", "LEFT", "center", "right", or "RIGHT" >> second value can be "top", "TOP", "center", "bottom", or "BOTTOM"
>> or this vector contains two numeric values between 0 and 1 that specifies the x and y value of the center of the text.
>> The uppercase values correspond to the position without margins (so tighter to the frame).tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
style = "quantile",
palette = "Blues",
title = "Dependency ratio") +
tm_layout(main.title = "Distribution of Dependency Ratio by planning subzone",
main.title.position = "center",
main.title.size = 1.2,
legend.height = 0.45,
legend.width = 0.35,
frame = TRUE,
asp = 0) +
tm_borders(alpha = 0.5) +
tm_compass(type="8star", size = 2) +
tm_scale_bar() +
tm_grid(alpha =0.2) +
tm_credits("Source: Planning Sub-zone boundary from Urban Redevelopment Authorithy (URA)\n and Population data from Department of Statistics DOS",
position = c("left", "bottom"))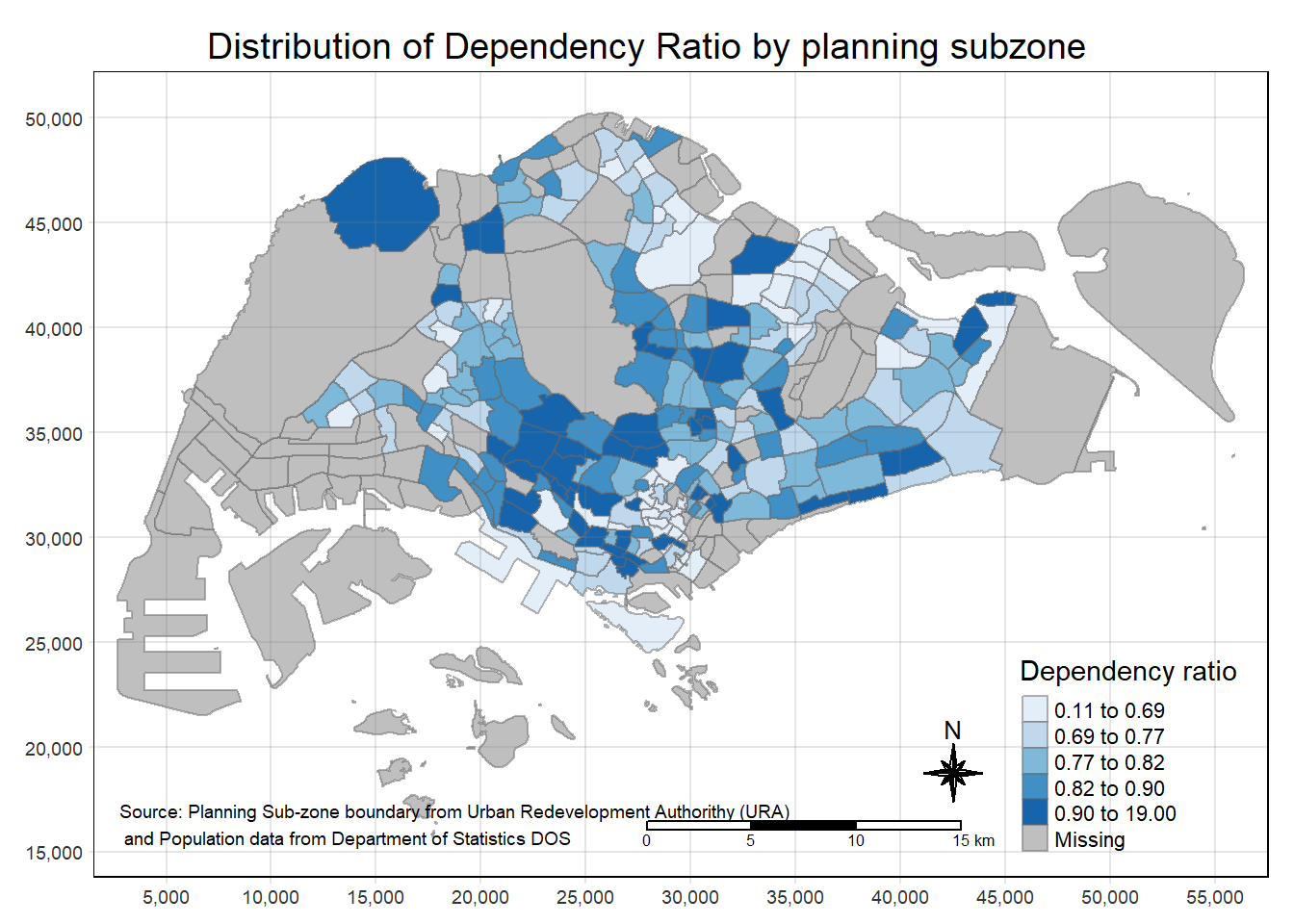
Following are the steps to reproduce above map.
Basic building block of tmap
tm_shape(mpsz_pop2020) +
tm_polygons()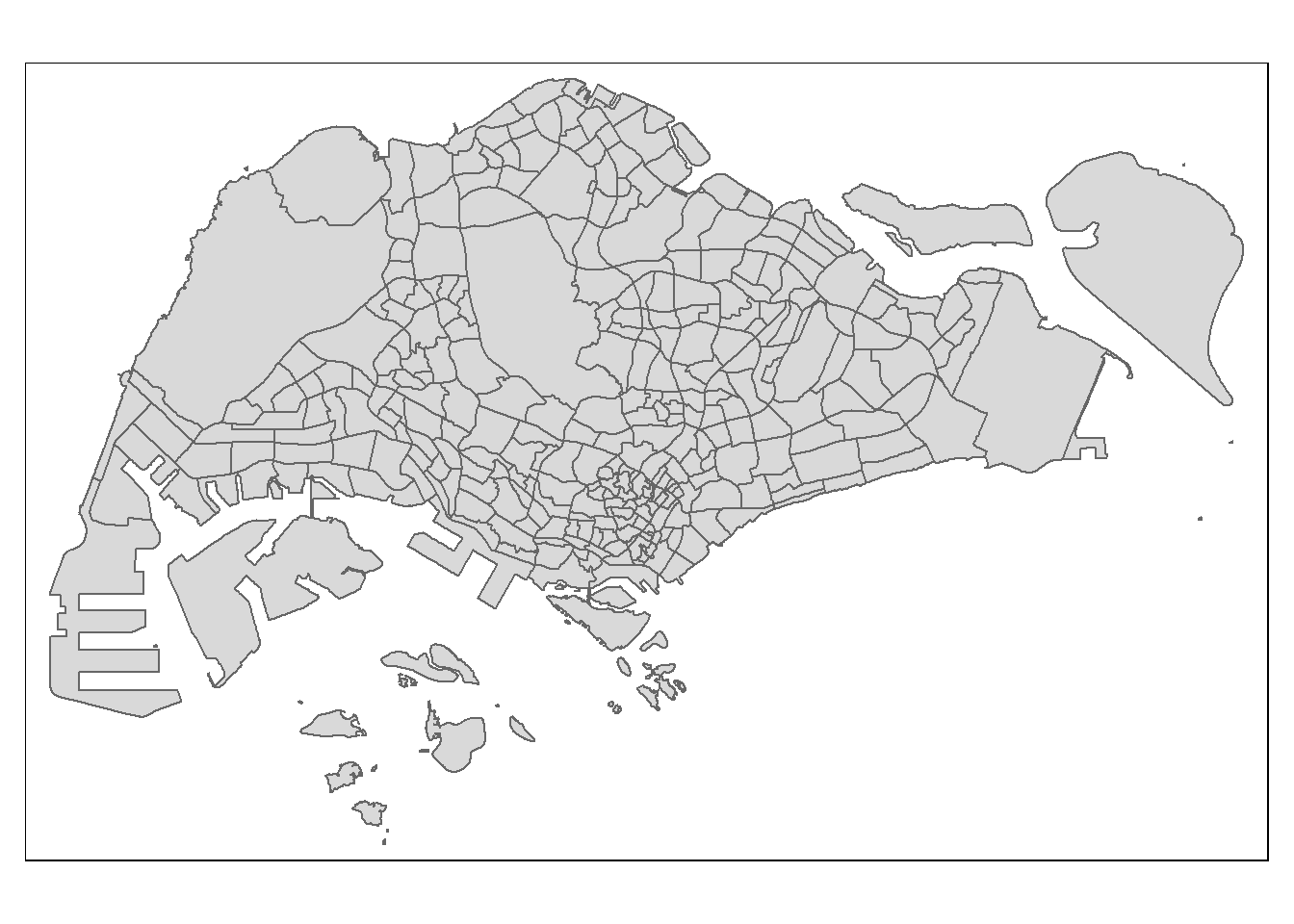
The default interval binning used to draw the choropleth map is called “pretty”. A detailed discussion of the data classification methods supported by tmap will be provided in sub-section 4.3.
The default colour scheme used is YlOrRd of ColorBrewer. You will learn more about the color scheme in sub-section 4.4.
By default, Missing value will be shaded in grey.
tm_shape(mpsz_pop2020)+
tm_polygons("DEPENDENCY")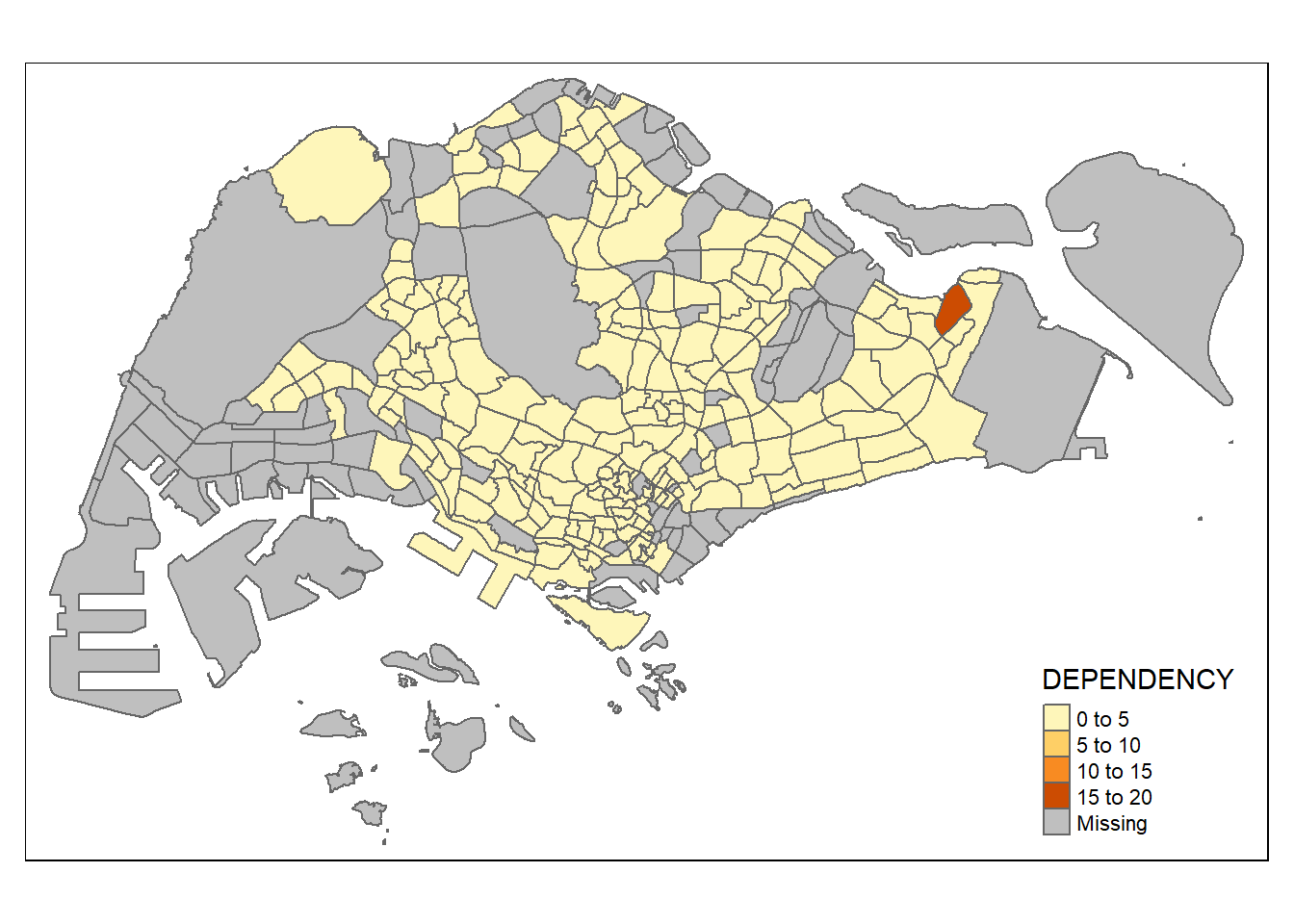
tm_polygons( ) is a wraper of tm_fill( ) & tm_border( ).
tm_fill( ) shades the polygons by using the default colour scheme.
tm_borders( ) adds the borders of the shapefile onto the choropleth map.
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY")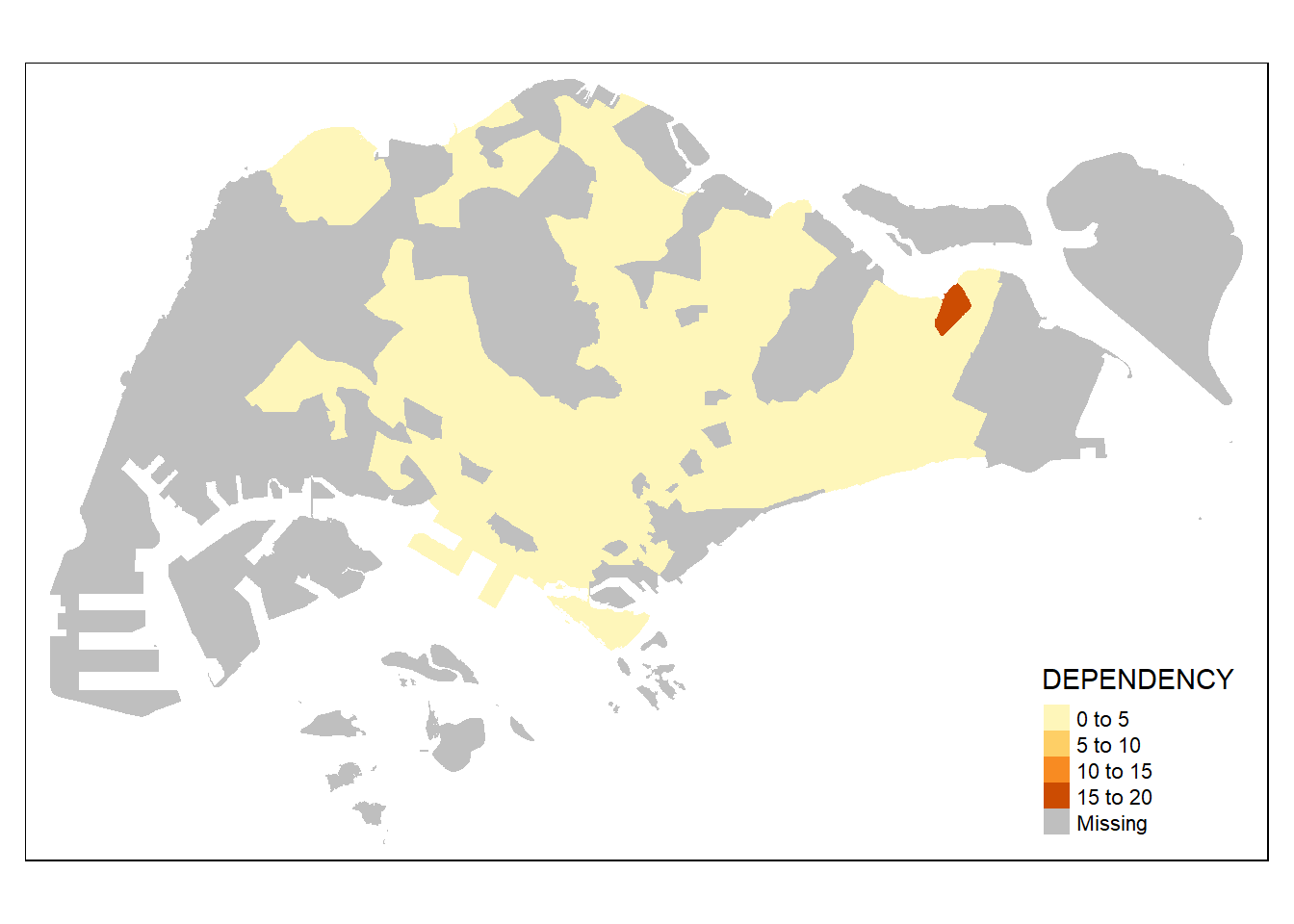
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY") +
tm_borders(lwd = 0.1, alpha = 1)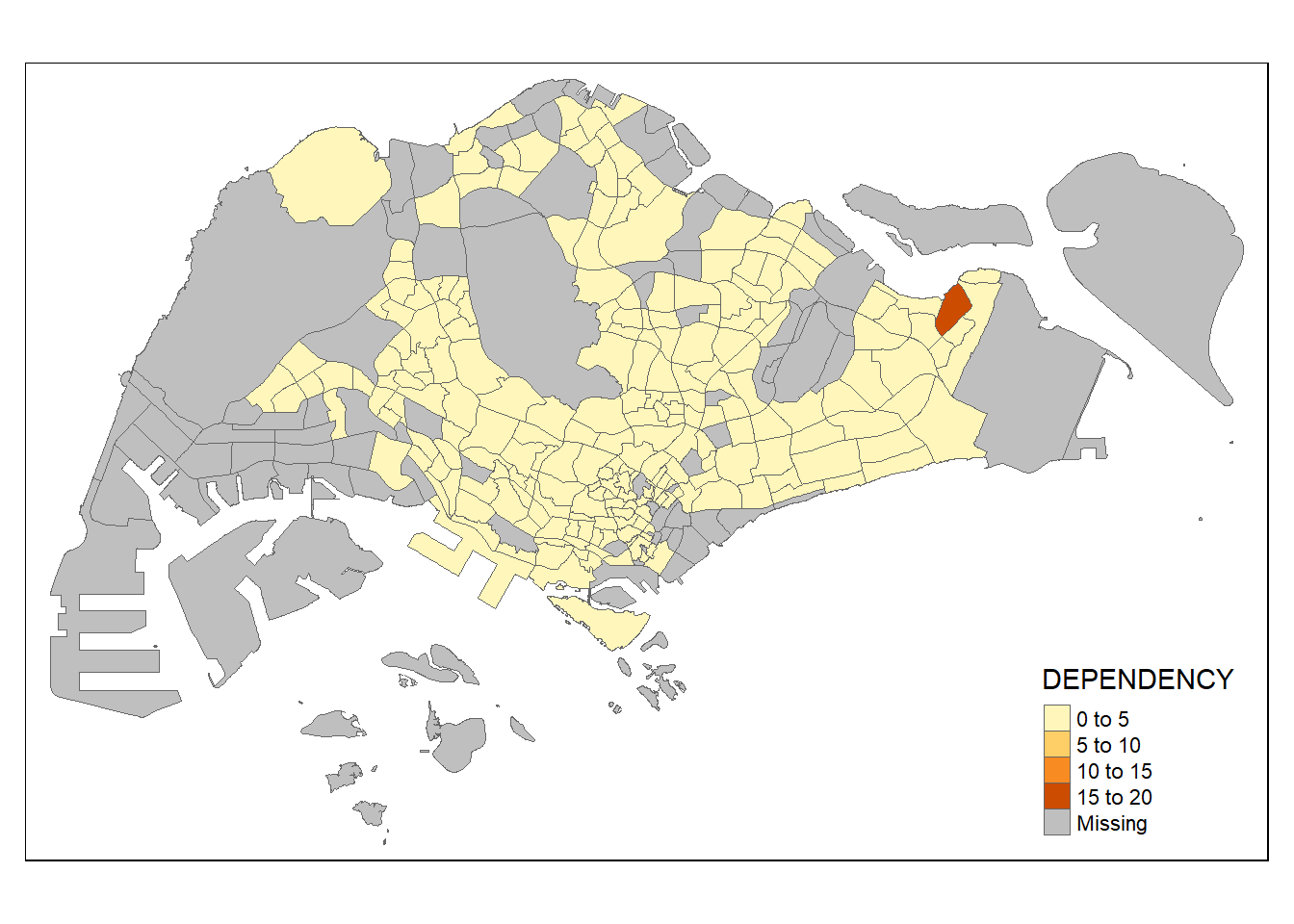
tmap provides a total ten data classification methods, namely: fixed, sd, equal, pretty (default), quantile, kmeans, hclust, bclust, fisher, and jenks.
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "jenks") +
tm_borders(alpha = 0.5)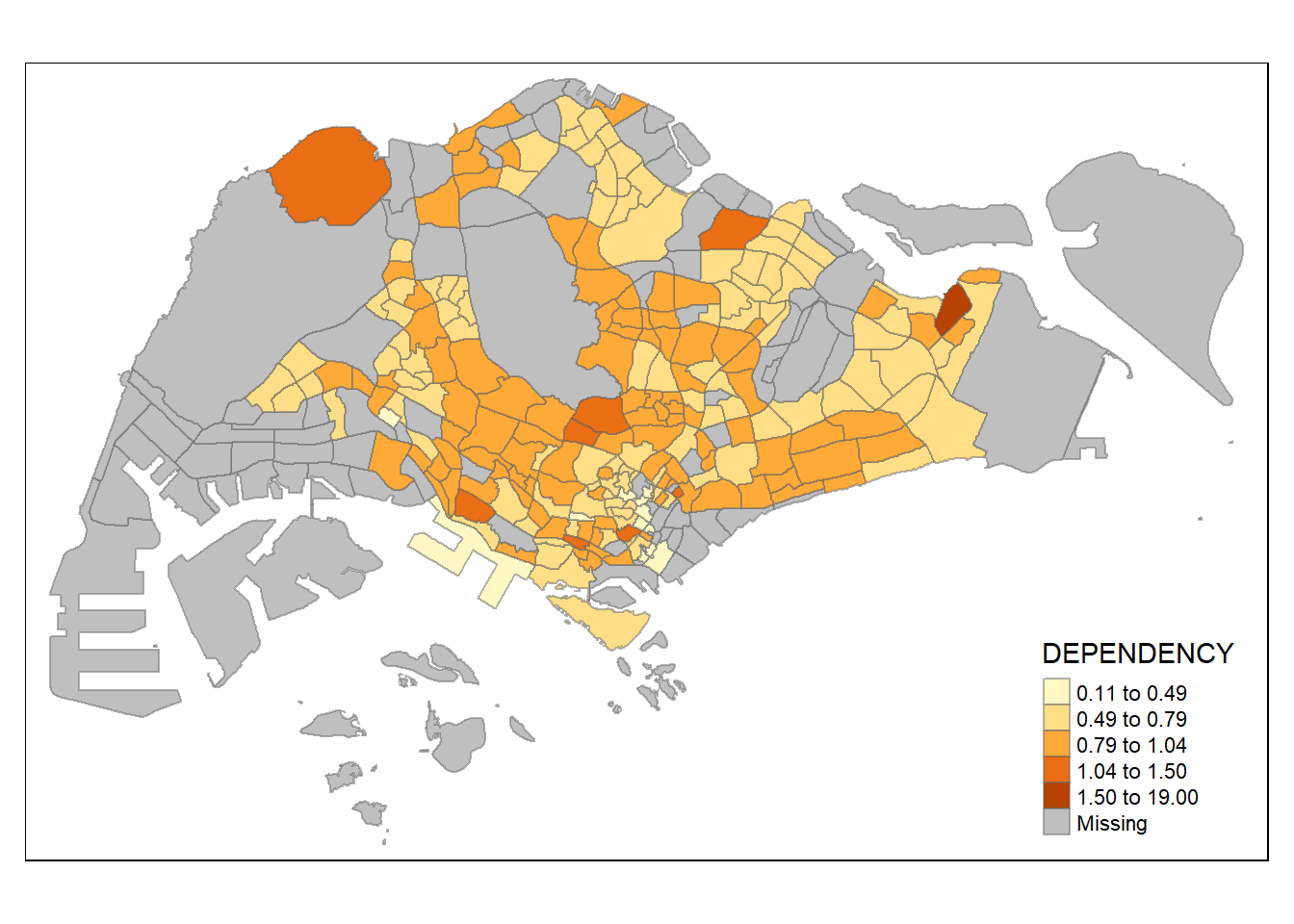
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "equal") +
tm_borders(alpha = 0.5)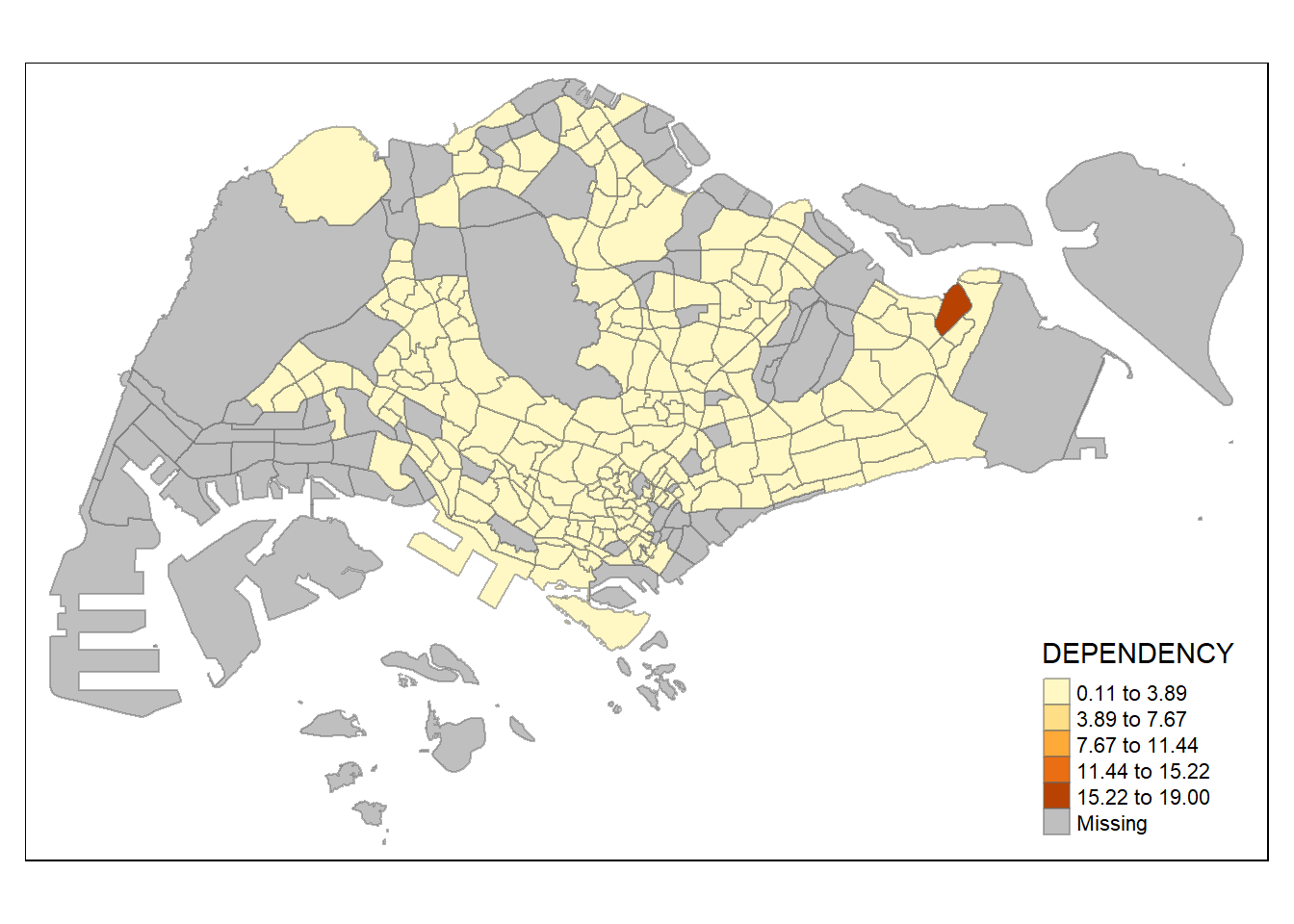
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "fixed",
breaks = c(0.0, 3.8, 7.6, 11.4, 15.2, 19.0)) +
tm_borders(alpha = 0.5)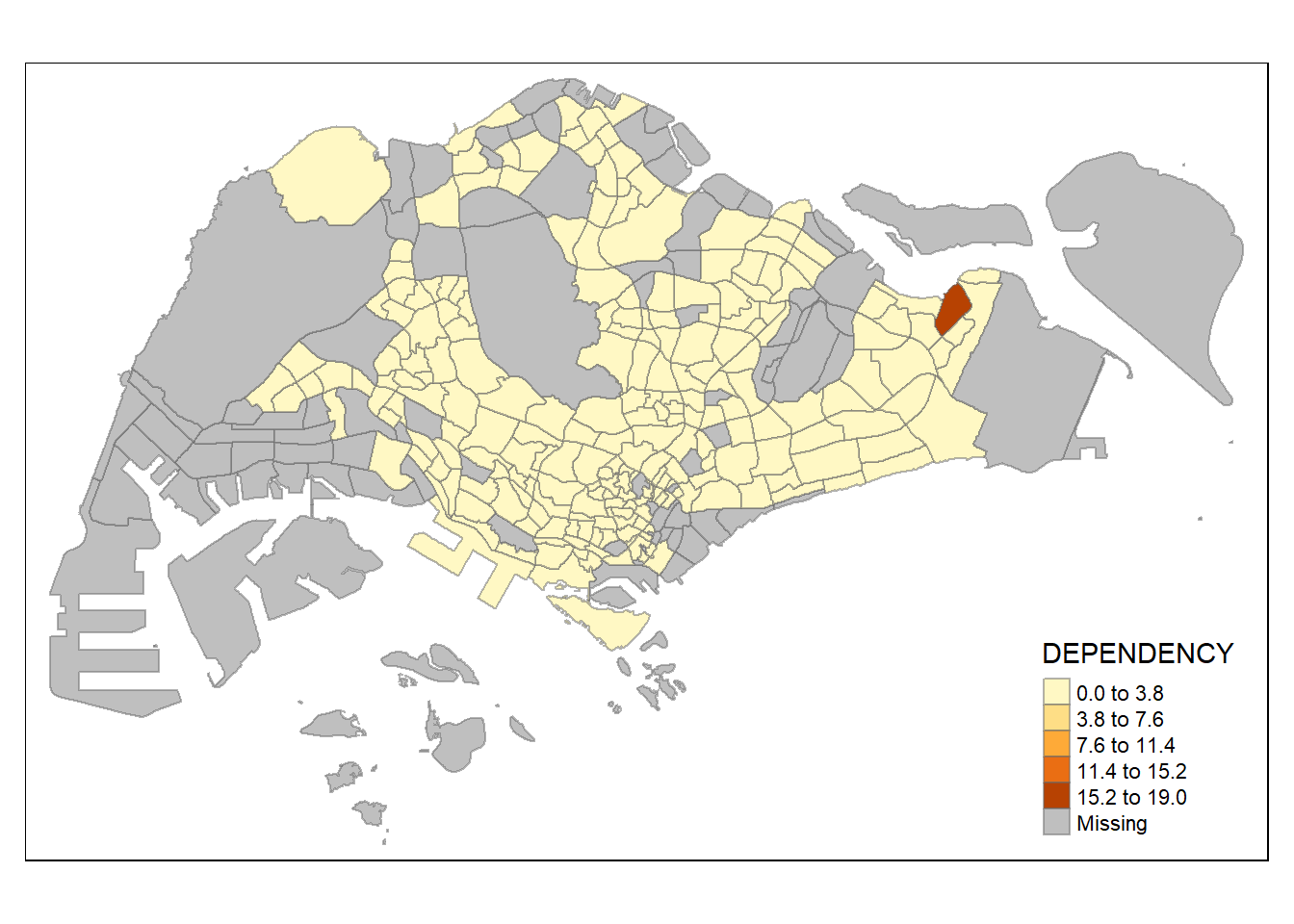
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "sd") +
tm_borders(alpha = 0.5)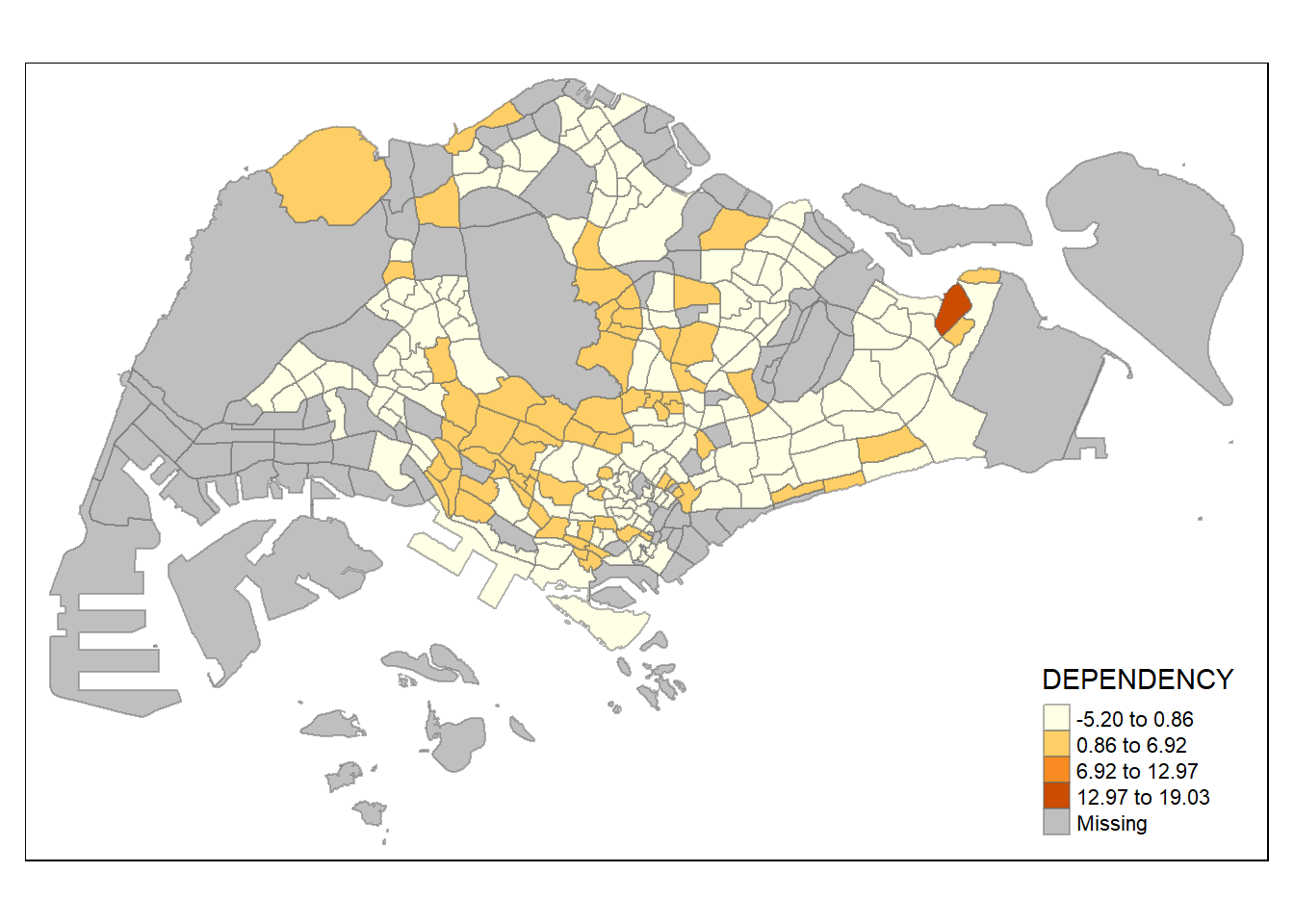
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "kmeans") +
tm_borders(alpha = 0.5)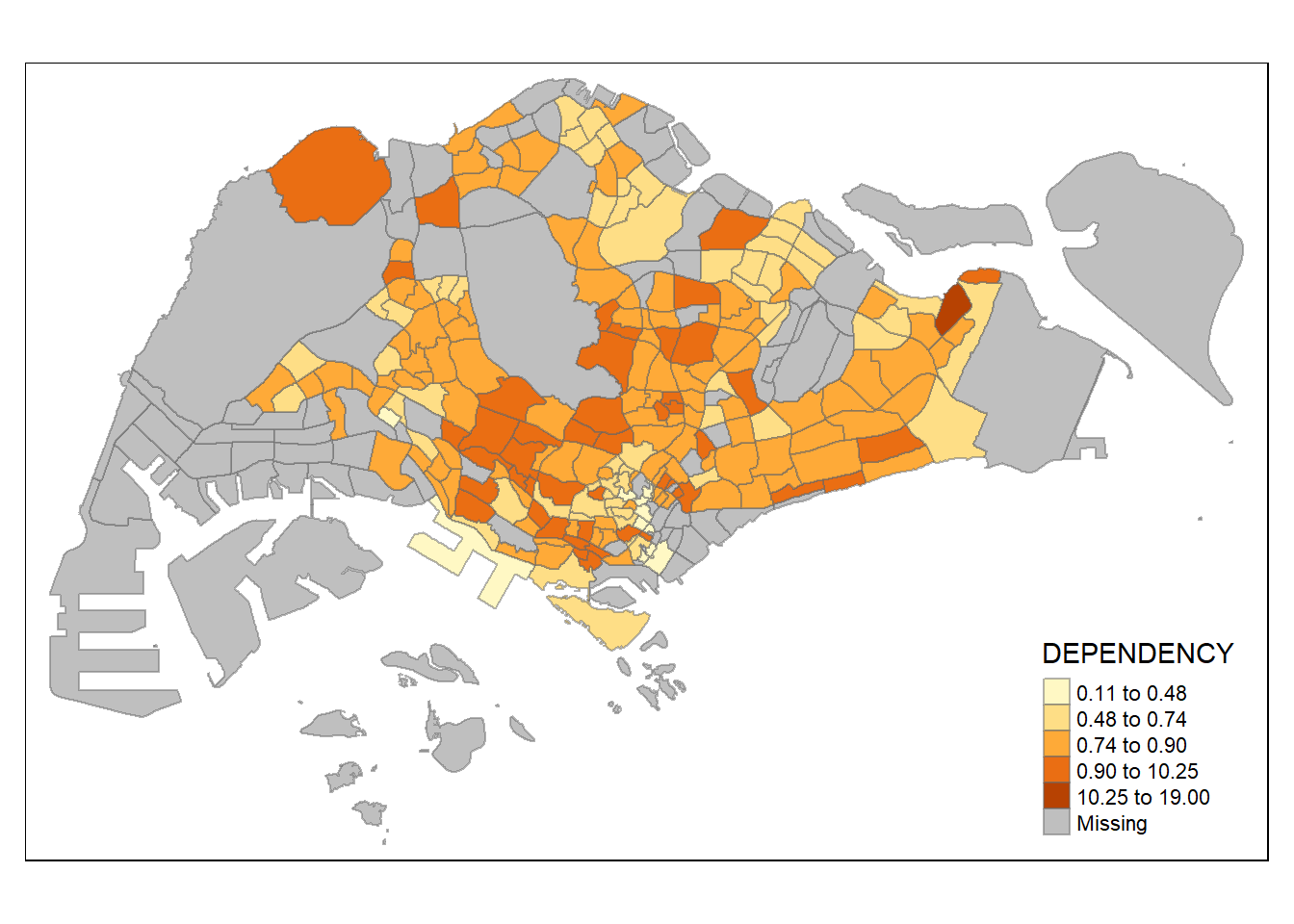
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "hclust") +
tm_borders(alpha = 0.5)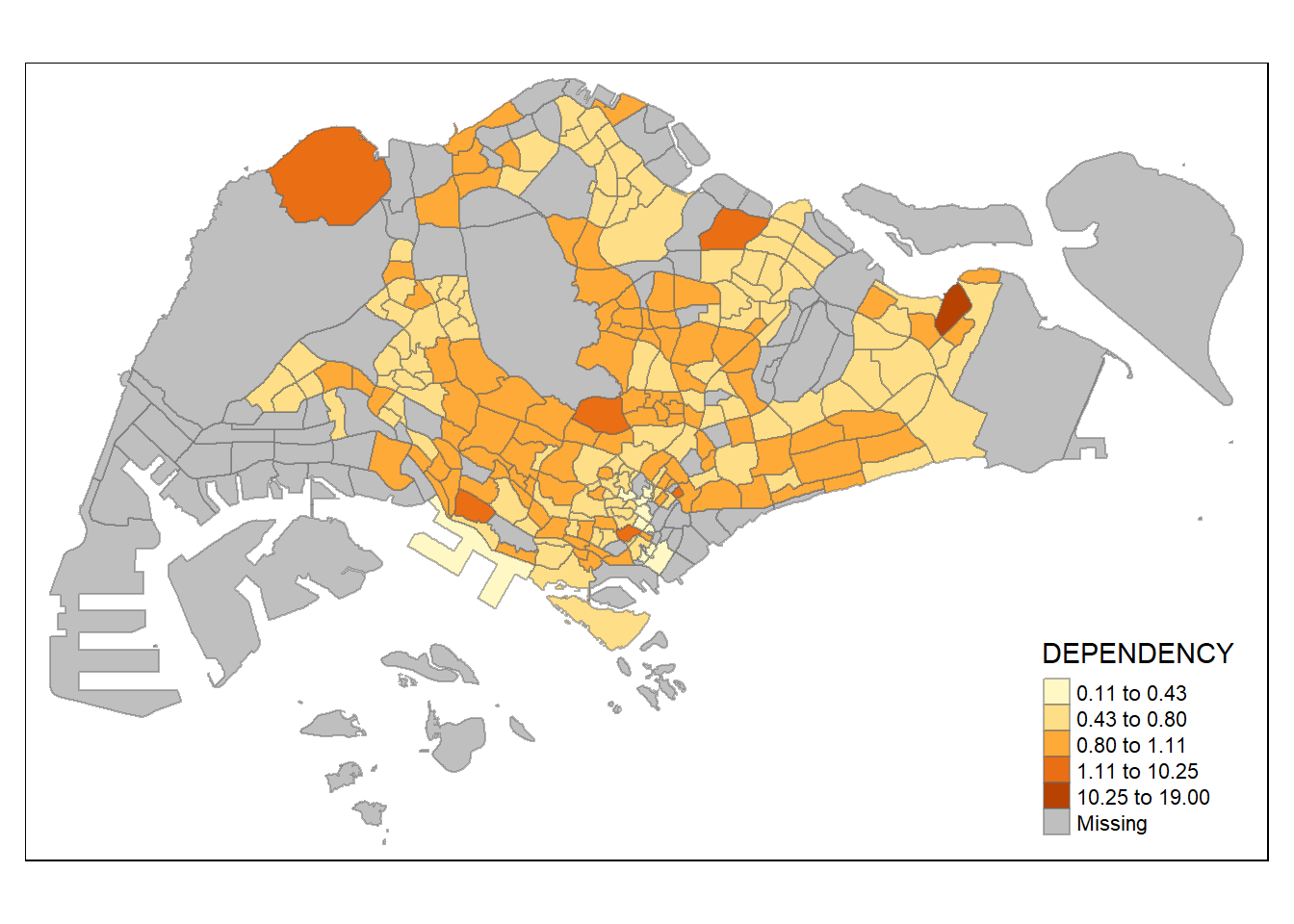
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "bclust") +
tm_borders(alpha = 0.5)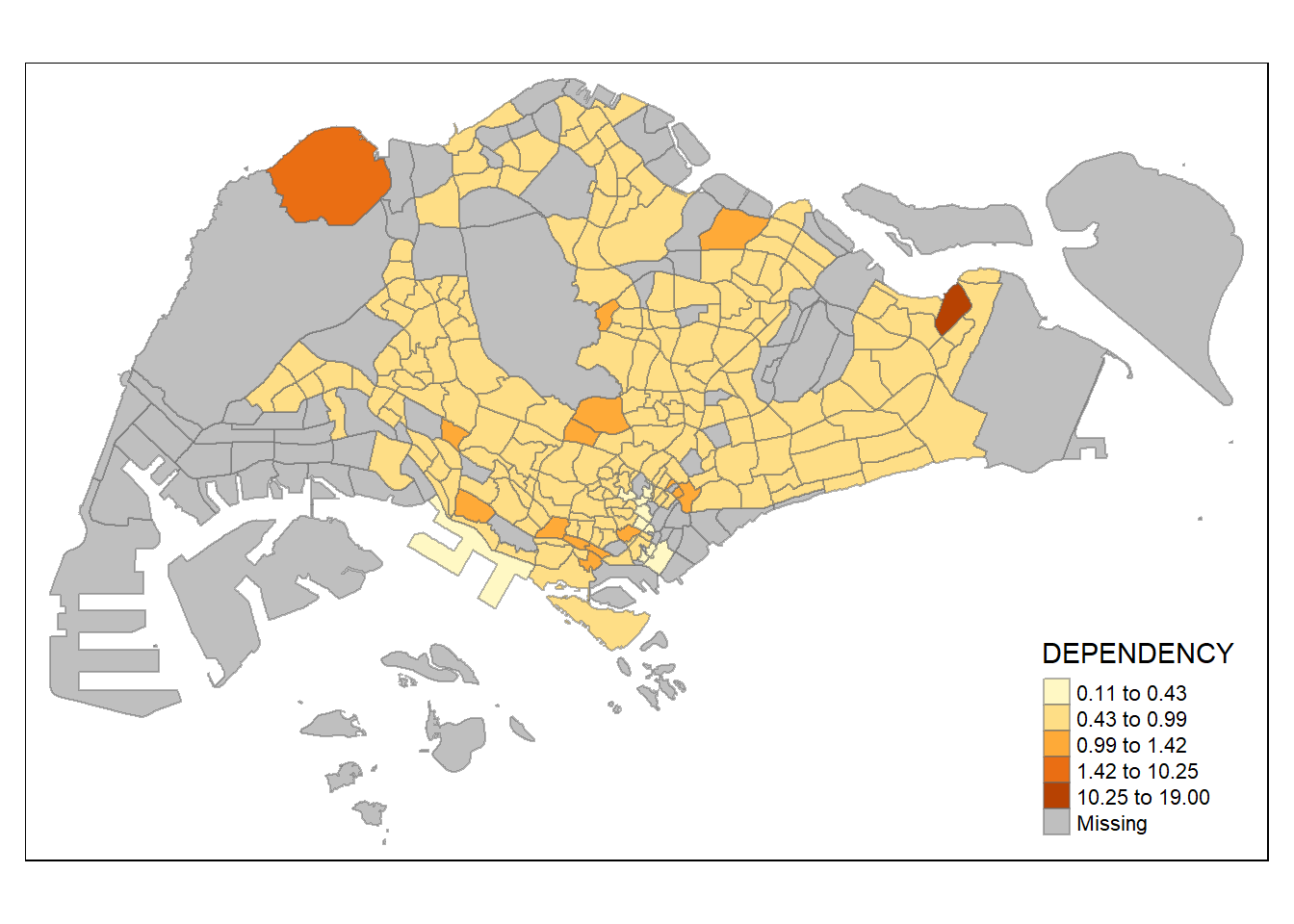
Committee Member: 1(1) 2(1) 3(1) 4(1) 5(1) 6(1) 7(1) 8(1) 9(1) 10(1)
Computing Hierarchical Clusteringtm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "fisher") +
tm_borders(alpha = 0.5)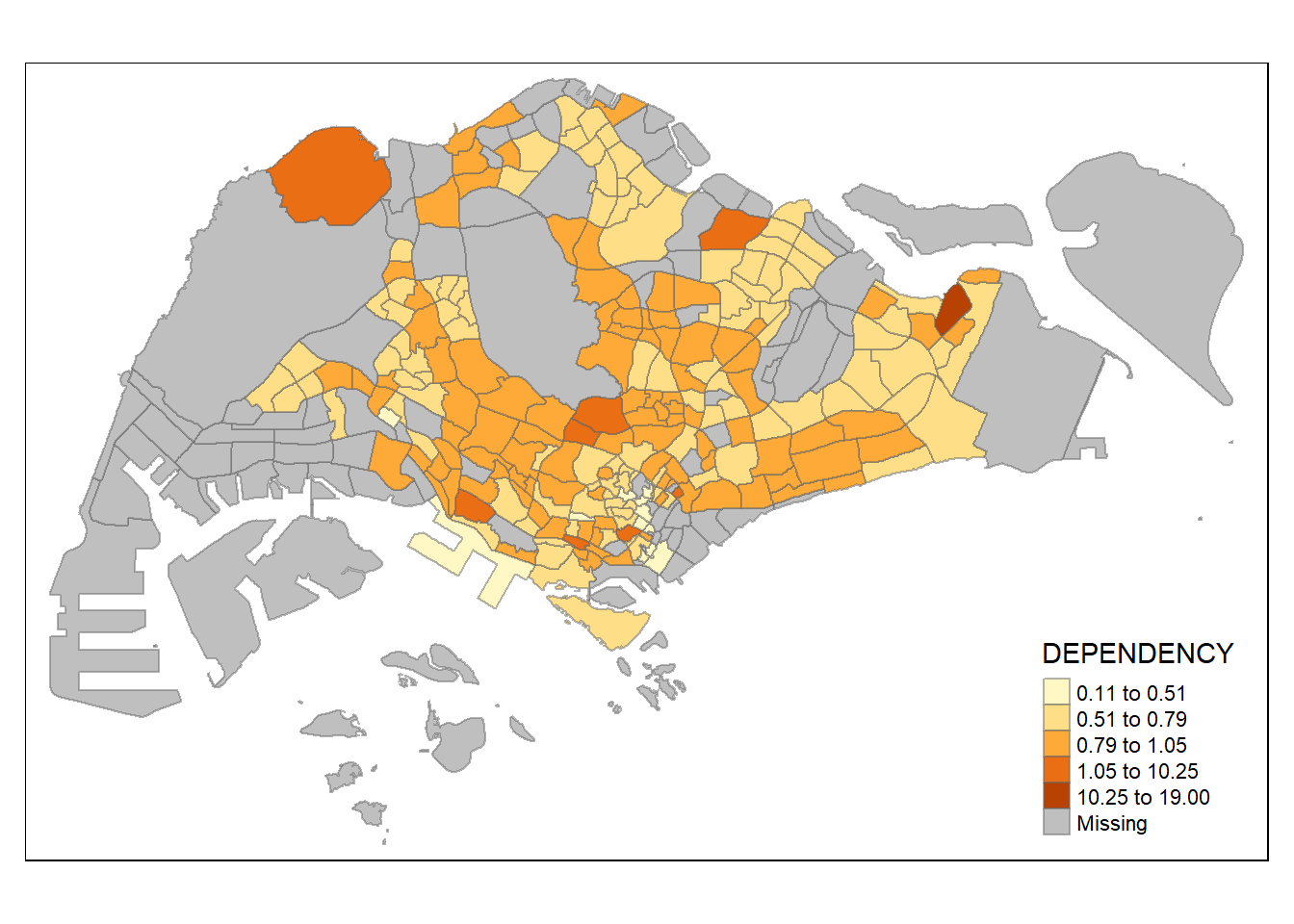
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 5,
style = "quantile") +
tm_borders(alpha = 0.5)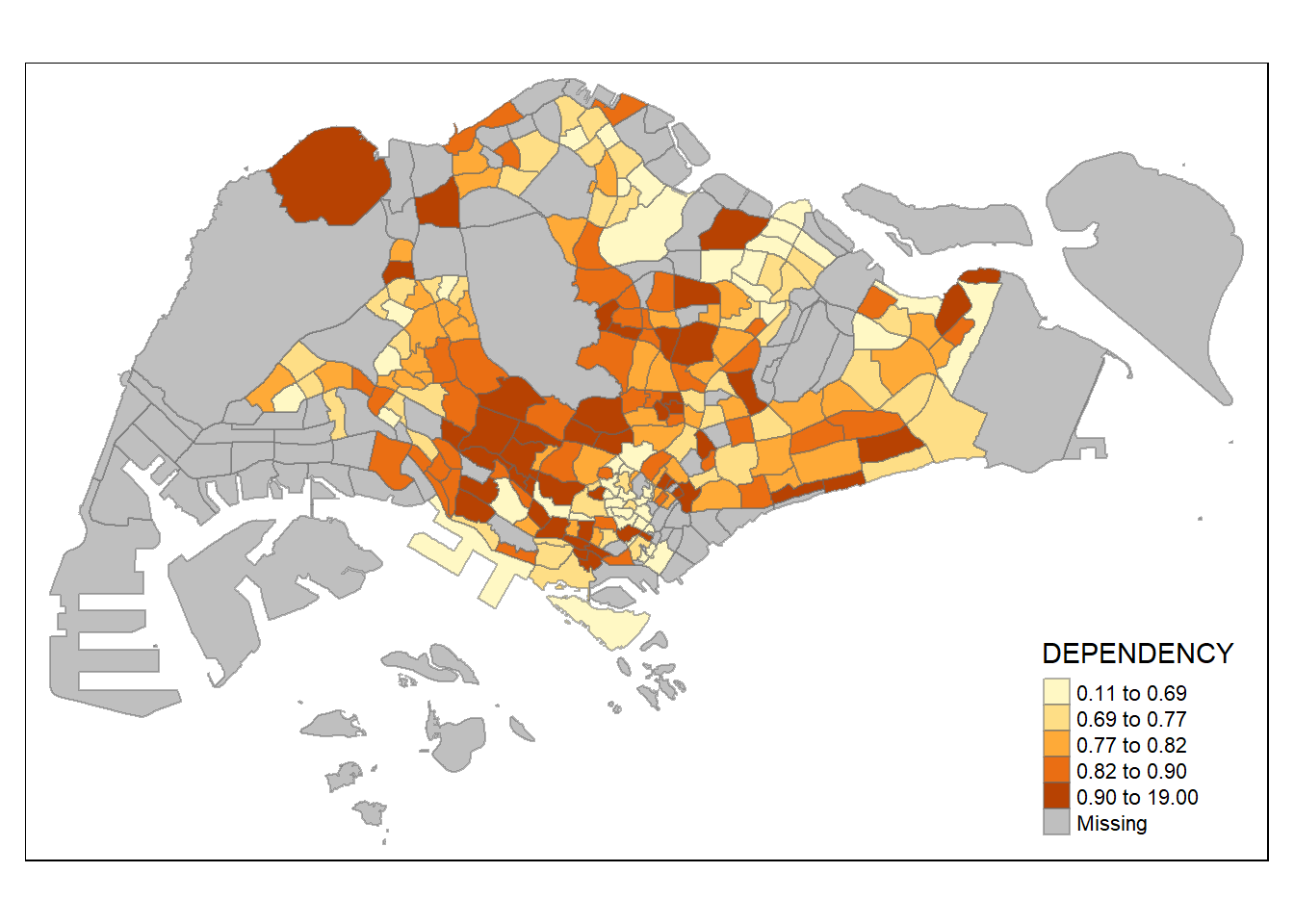
DIY: Preparing choropleth maps by using similar classification method but with different numbers of classes (i.e. 2, 6, 10, 20). Compare the output maps, what observation can you draw?
Tmap breaks require a minimum and maximum.
In order to end up with n categories, n+1 elements must be specified in the breaks option (the values must be in increasing order).
Before setting the break points, use summary( ) to compute descriptive statistics of the “DEPENDENCY” variable.
summary(mpsz_pop2020$DEPENDENCY) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.1111 0.7147 0.7866 0.8585 0.8763 19.0000 92 Set break point at 0.60, 0.70, 0.80, and 0.90.
Need to include a minimum and maximum, which set at 0 and 100.
Breaks vector is thus c(0, 0.60, 0.70, 0.80, 0.90, 1.00)
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
breaks = c(0, 0.60, 0.70, 0.80, 0.90, 1.00)) +
tm_borders(alpha = 0.5)Warning: Values have found that are higher than the highest break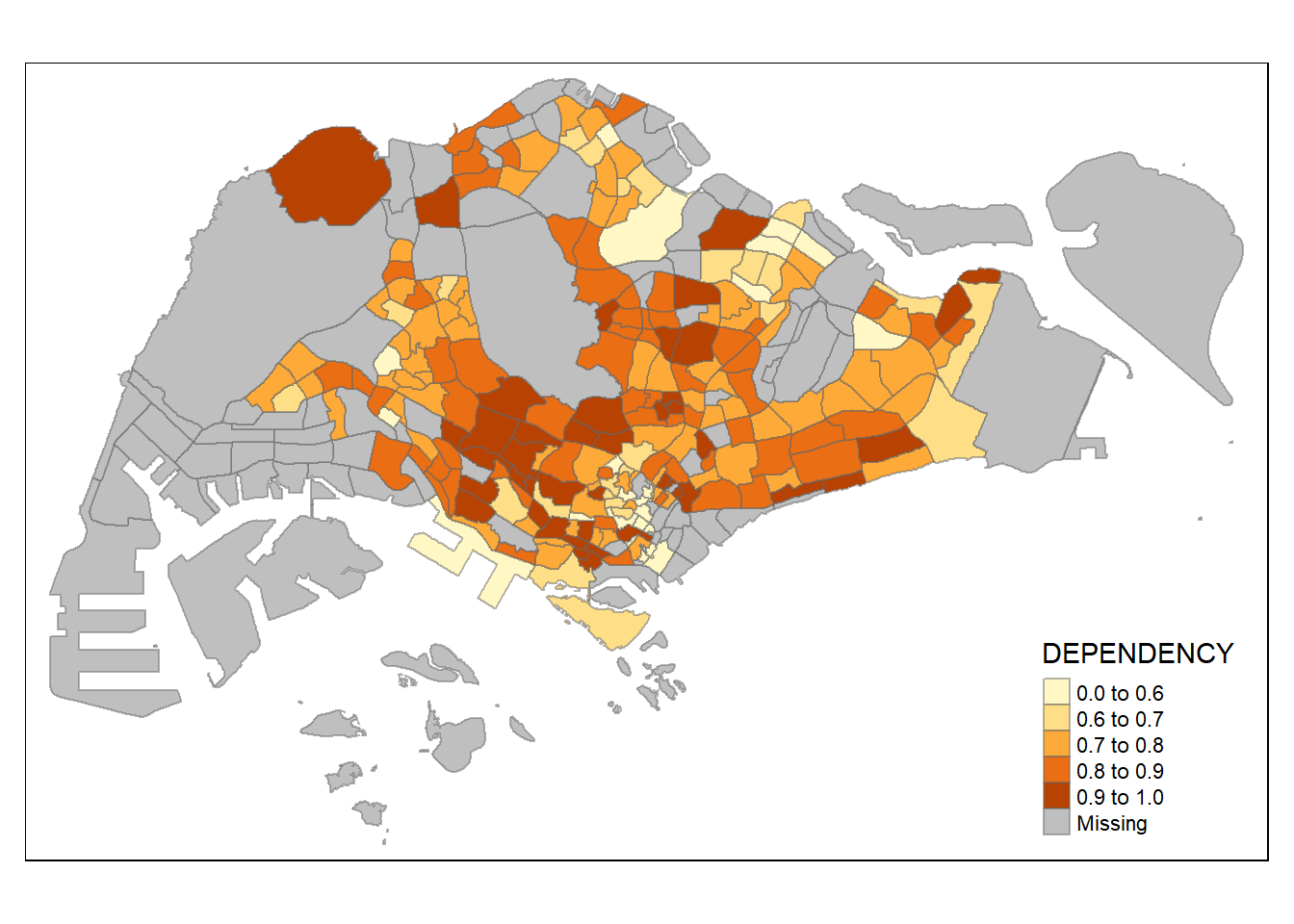
quick reference for ColorBrewer 2.0 colour options
use palette argument in tm_fill( )
without “-” prefix, darker shade = higher value
with “-” prefix to reverse colour scheme, darker shade = smaller value
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 6,
style = "quantile",
palette = "Blues") +
tm_borders(alpha = 0.5)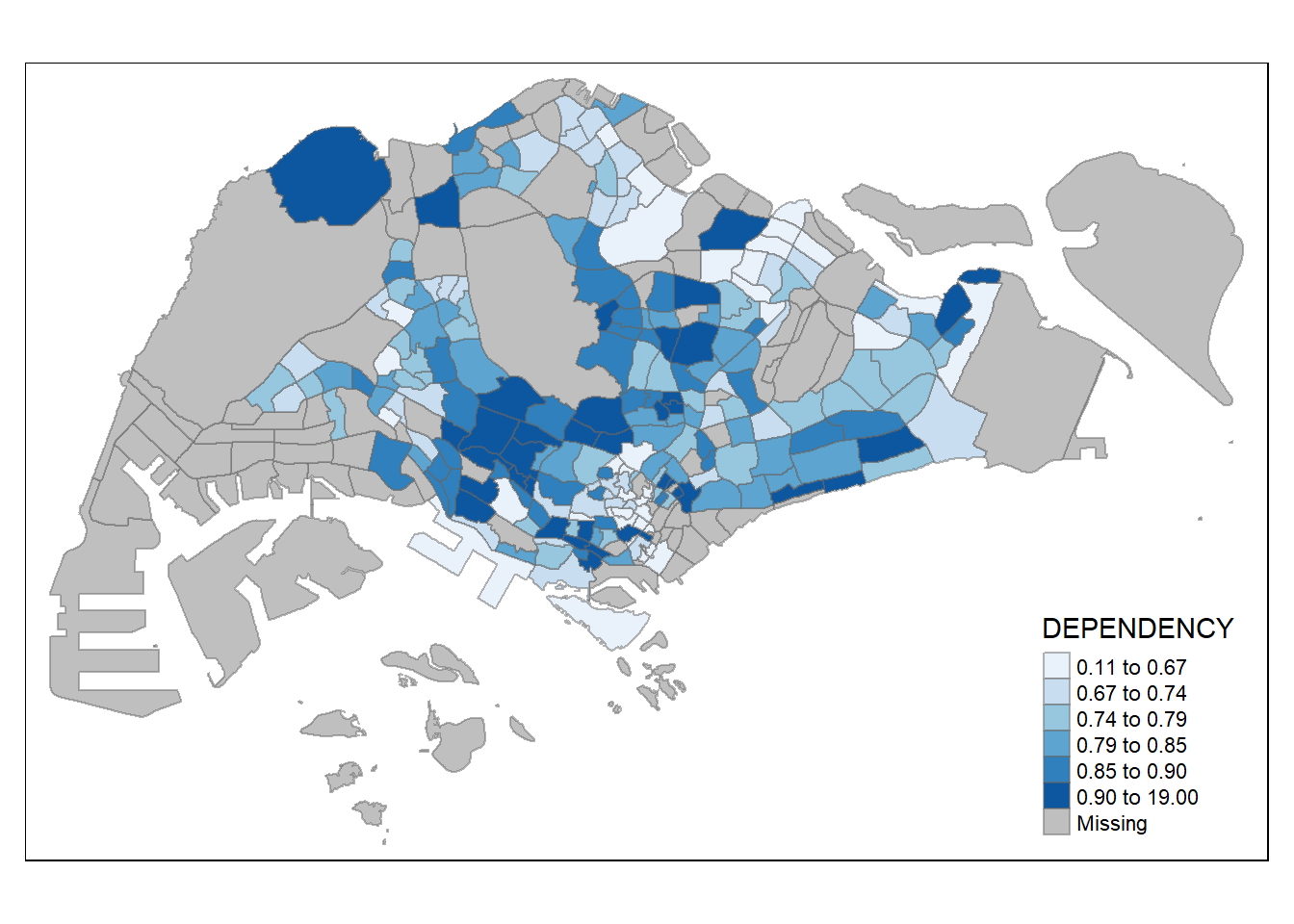
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
n = 6,
style = "quantile",
palette = "-Blues") +
tm_borders(alpha = 0.5)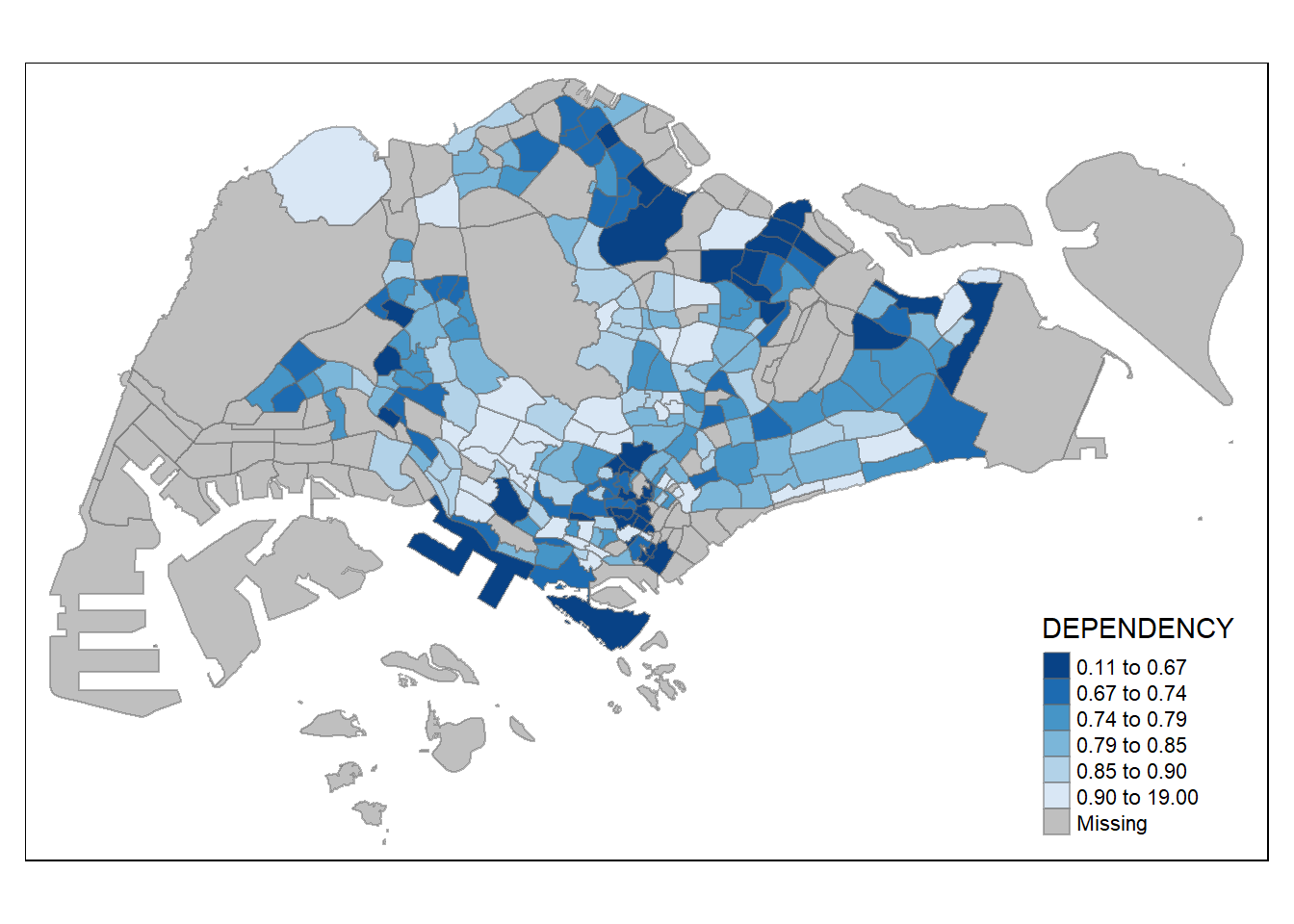
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
style = "quantile",
palette = "-Greens") +
tm_borders(alpha = 0.5)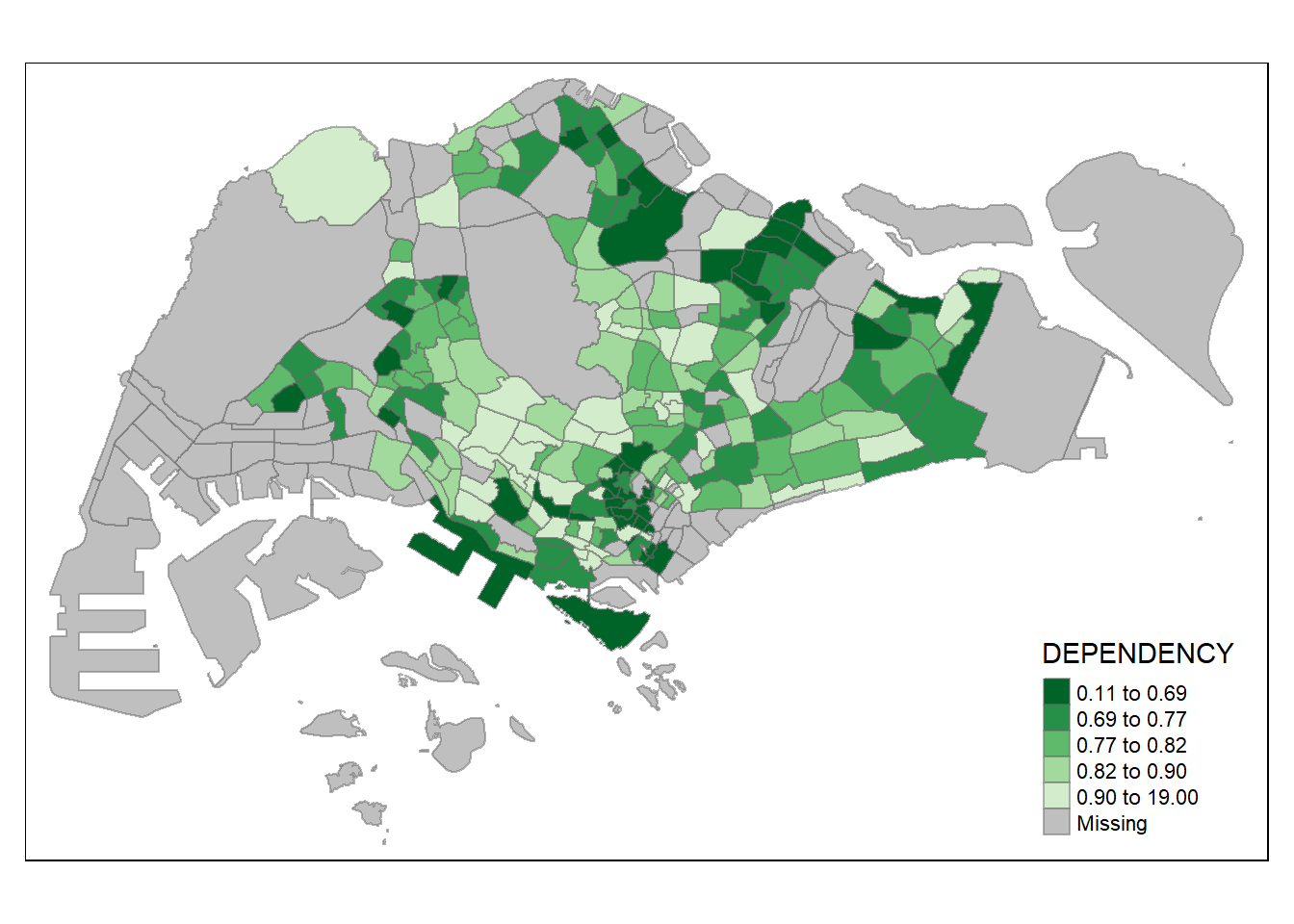
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
style = "jenks",
palette = "Blues",
legend.hist = TRUE,
legend.is.portrait = TRUE,
legend.hist.z = 0.1) +
tm_layout(main.title = "Distribution of Dependency Ratio by planning subzone \n(Jenks classification)",
main.title.position = "center",
main.title.size = 1,
legend.height = 0.45,
legend.width = 0.35,
legend.outside = FALSE,
legend.position = c("right", "bottom"),
frame = FALSE) +
tm_borders(alpha = 0.5)
use tmap_style( ) function.
the default style is “white”.
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
style = "quantile",
palette = "-Greens") +
tm_borders(alpha = 0.5) +
tmap_style("classic")tmap style set to "classic"other available styles are: "white", "gray", "natural", "cobalt", "col_blind", "albatross", "beaver", "bw", "watercolor" 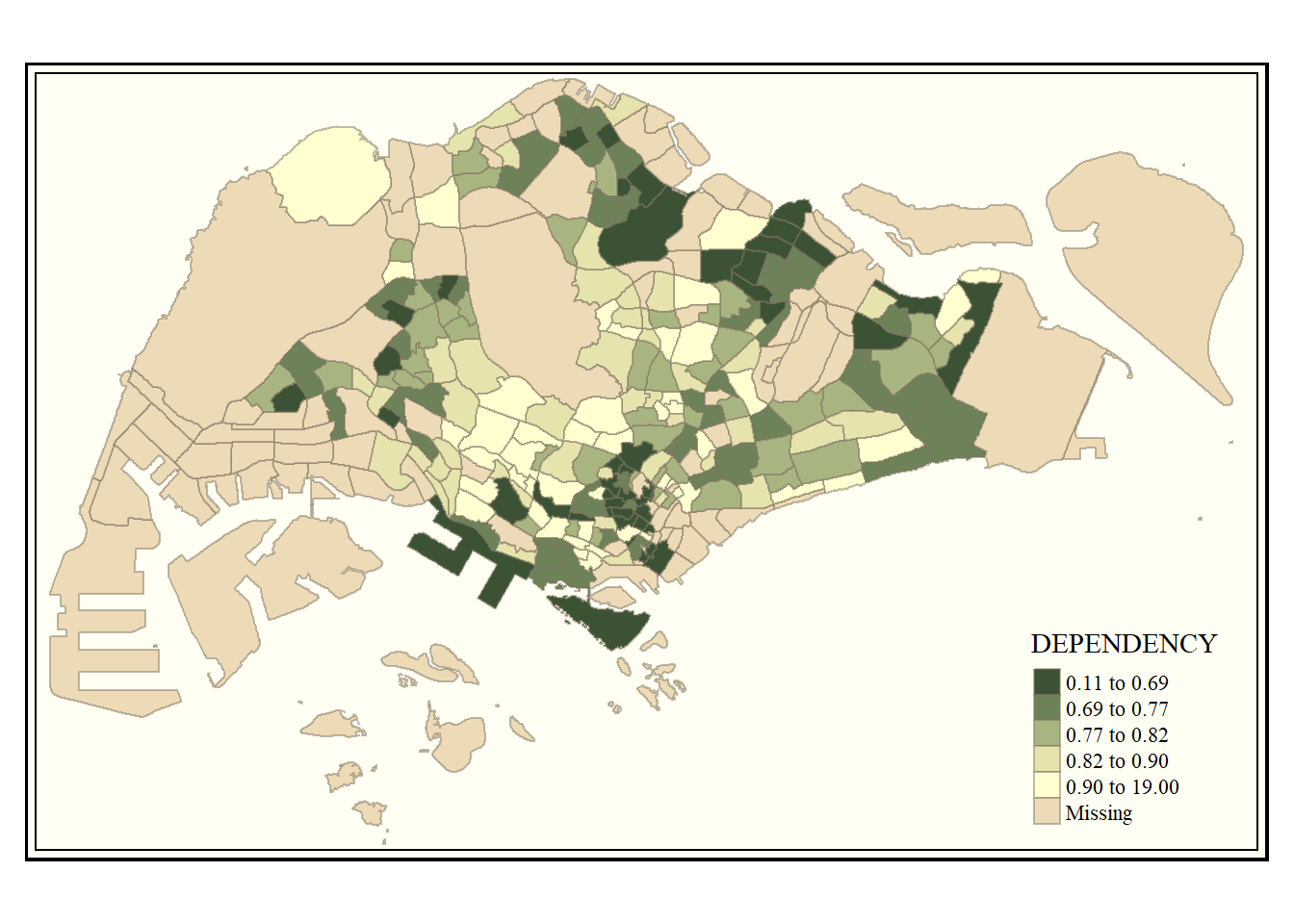
Other map furniture such as compass, scale bar, grid lines, etc.
tm_shape(mpsz_pop2020)+
tm_fill("DEPENDENCY",
style = "quantile",
palette = "Blues",
title = "No. of persons") +
tm_layout(main.title = "Distribution of Dependency Ratio \nby planning subzone",
main.title.position = "center",
main.title.size = 1.2,
legend.height = 0.45,
legend.width = 0.35,
frame = TRUE) +
tm_borders(alpha = 0.5) +
tm_compass(type="8star", size = 2) +
tm_scale_bar(width = 0.15) +
tm_grid(lwd = 0.1, alpha = 0.2) +
tm_credits("Source: Planning Sub-zone boundary from Urban Redevelopment Authorithy (URA)\n and Population data from Department of Statistics DOS",
position = c("left", "bottom"))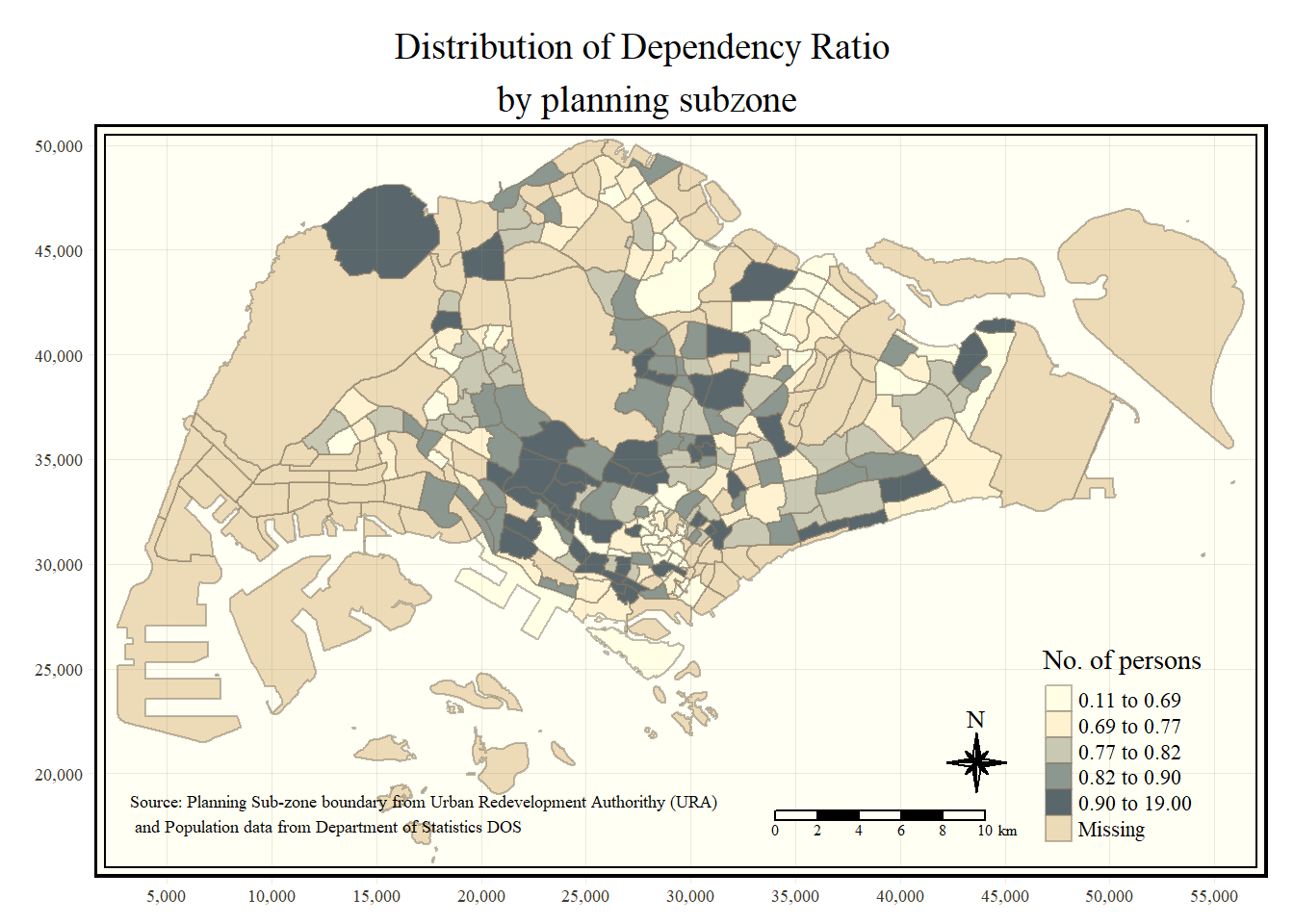
tmap_style("white")tmap style set to "white"other available styles are: "gray", "natural", "cobalt", "col_blind", "albatross", "beaver", "bw", "classic", "watercolor" Small multiple maps (smm), also referred to as facet maps, are composed of many maps arrange side-by-side, and sometimes stacked vertically.
In tmap, can be plotted in 3 ways:
by assigning multiple values to at least one of the asthetic arguments,
by defining a group-by variable in tm_facets( ), and
by creating multiple stand-alone maps with tmap_arrange( ).
tm_shape(mpsz_pop2020)+
tm_fill(c("YOUNG", "AGED"),
style = "equal",
palette = "Blues") +
tm_layout(legend.position = c("right", "bottom")) +
tm_borders(alpha = 0.5) +
tmap_style("white")tmap style set to "white"other available styles are: "gray", "natural", "cobalt", "col_blind", "albatross", "beaver", "bw", "classic", "watercolor" 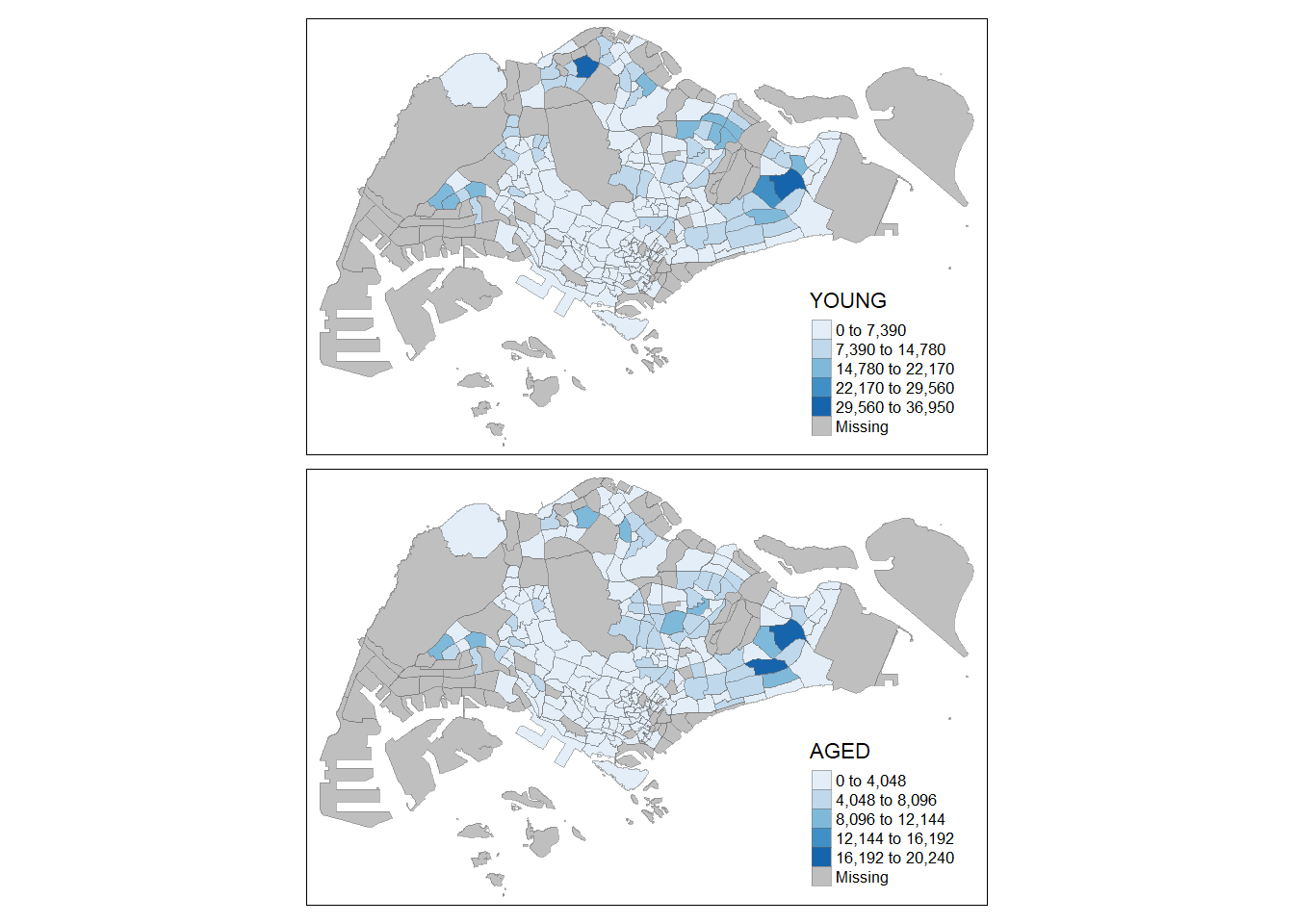
tm_shape(mpsz_pop2020)+
tm_polygons(c("DEPENDENCY","AGED"),
style = c("equal", "quantile"),
palette = list("Blues","Greens")) +
tm_layout(legend.position = c("right", "bottom"))
tm_shape(mpsz_pop2020) +
tm_fill("DEPENDENCY",
style = "quantile",
palette = "Blues",
thres.poly = 0) +
tm_facets(by="REGION_N",
free.coords=TRUE,
drop.shapes=TRUE) +
tm_layout(legend.show = FALSE,
title.position = c("center", "center"),
title.size = 20) +
tm_borders(alpha = 0.5)Warning: The argument drop.shapes has been renamed to drop.units, and is
therefore deprecated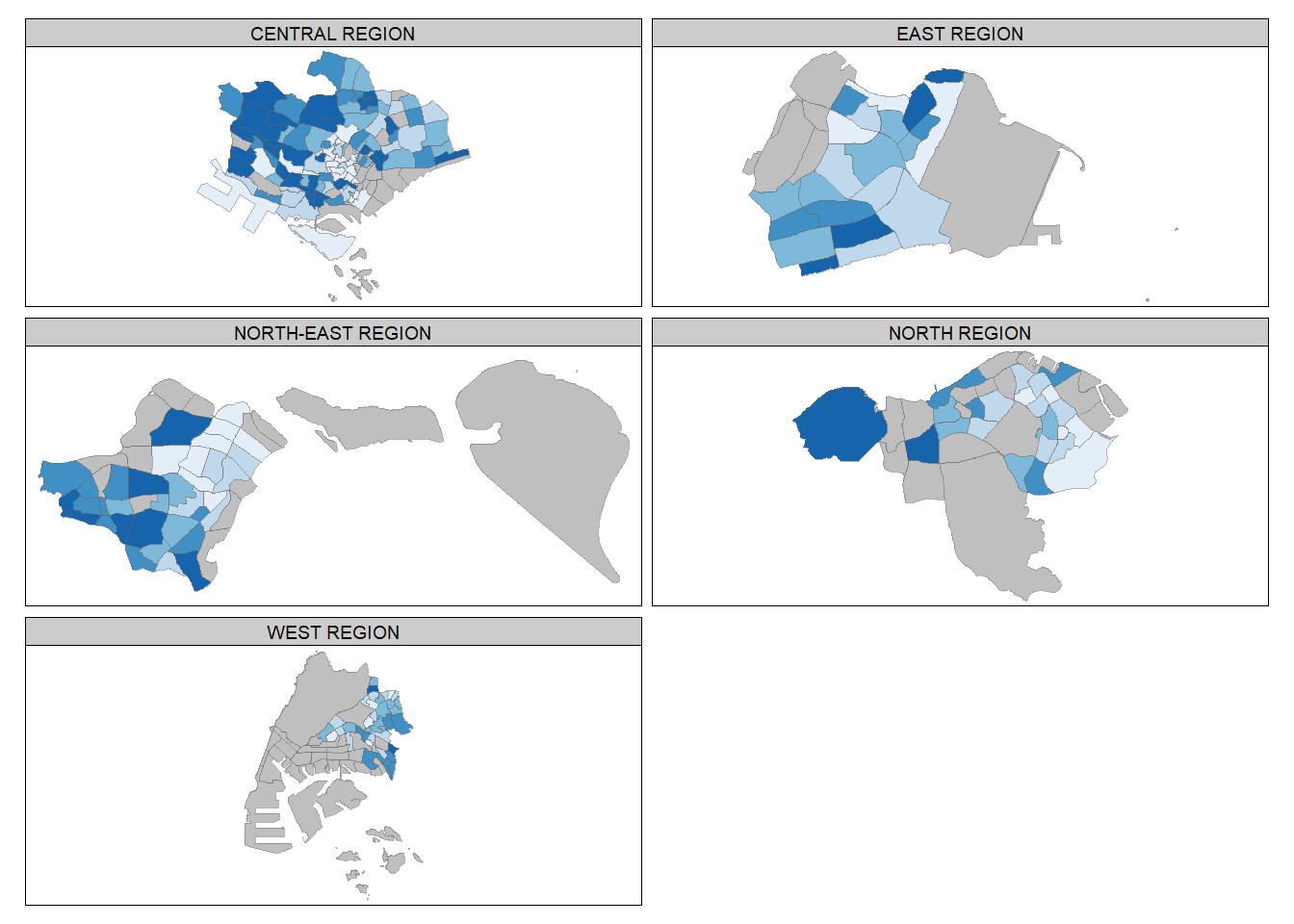
youngmap <- tm_shape(mpsz_pop2020)+
tm_polygons("YOUNG",
style = "quantile",
palette = "Blues")
agedmap <- tm_shape(mpsz_pop2020)+
tm_polygons("AGED",
style = "quantile",
palette = "Blues")
tmap_arrange(youngmap, agedmap, asp=1, ncol=2)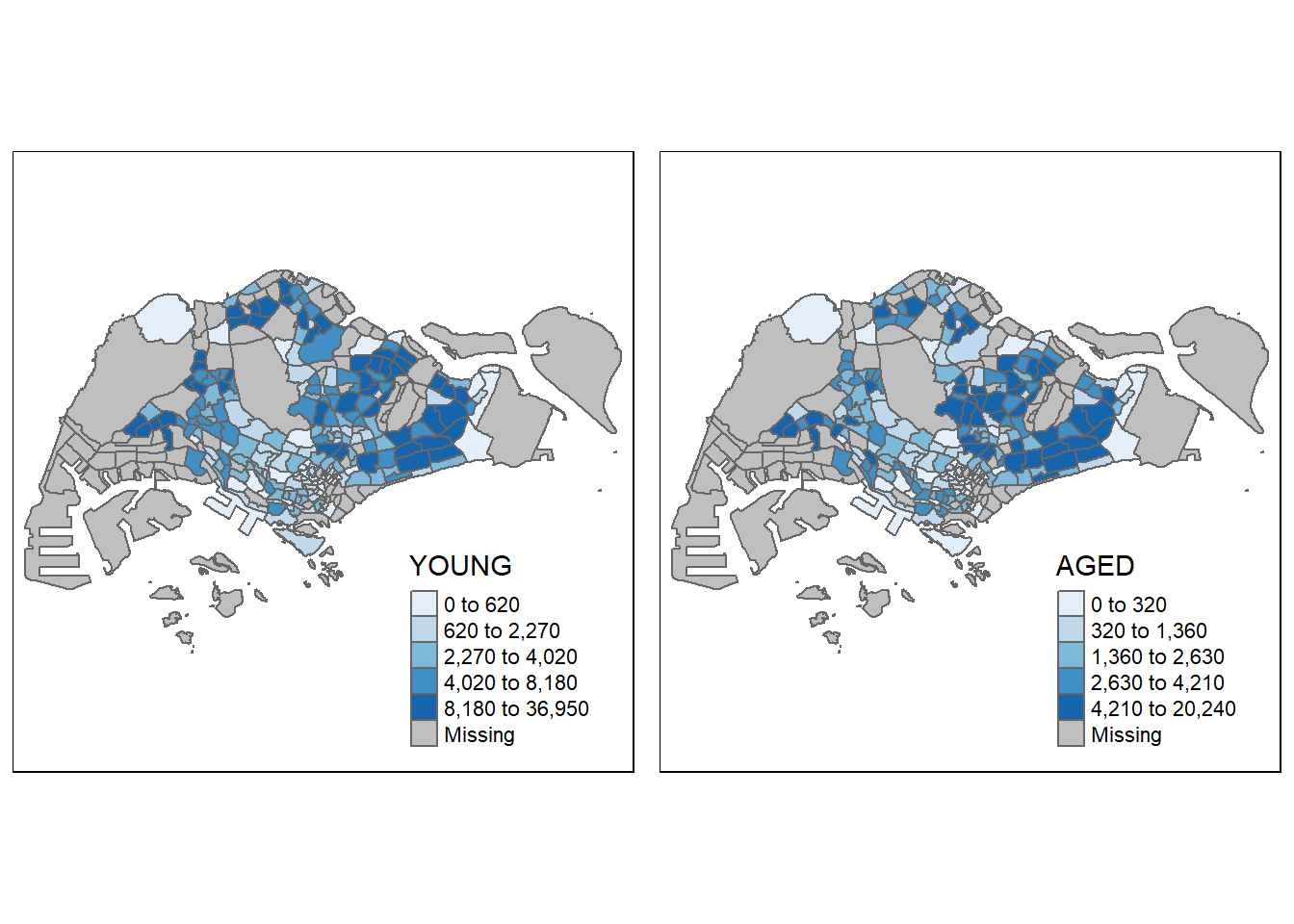
tm_shape(mpsz_pop2020[mpsz_pop2020$REGION_N=="CENTRAL REGION", ])+
tm_fill("DEPENDENCY",
style = "quantile",
palette = "Blues",
legend.hist = TRUE,
legend.is.portrait = TRUE,
legend.hist.z = 0.1) +
tm_layout(legend.outside = TRUE,
legend.height = 0.45,
legend.width = 5.0,
legend.position = c("right", "bottom"),
frame = FALSE) +
tm_borders(alpha = 0.5)Warning in pre_process_gt(x, interactive = interactive, orig_crs =
gm$shape.orig_crs): legend.width controls the width of the legend within a map.
Please use legend.outside.size to control the width of the outside legend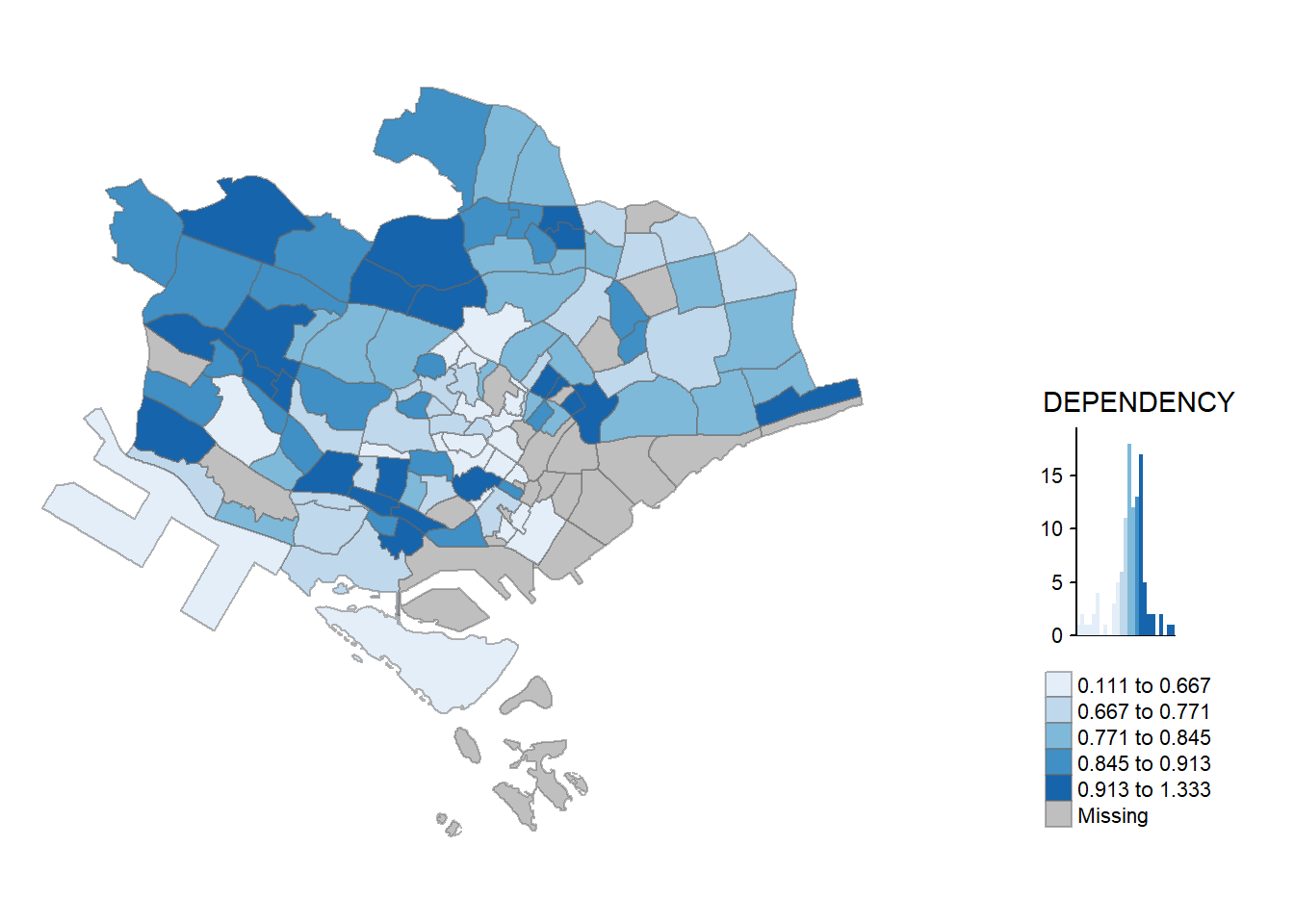
Datacamp. Writing.rds files. https://campus.datacamp.com/courses/reading-data-into-r-with-readr/importing-data-with-readr?ex=7
Dplyr.tidyverse.org. Mutate multiple columns. https://dplyr.tidyverse.org/reference/mutate_all.html
qtm: Quick thematic map plot. https://www.rdocumentation.org/packages/tmap/versions/3.3-3/topics/qtm
r4gdsa.netlify.app. https://r4gdsa.netlify.app/chap02.html#data-preparation
Rdocumentation.org. tm_shape: Specify the shape object. https://www.rdocumentation.org/packages/tmap/versions/3.3-3/topics/tm_shape
Tidyr.tidyverse.org. Pivot data from long to wide. https://tidyr.tidyverse.org/reference/pivot_wider.html